As large language models (LLMs) increasingly power autonomous agents—from customer service bots to system administration tools—a critical question arises: Can…
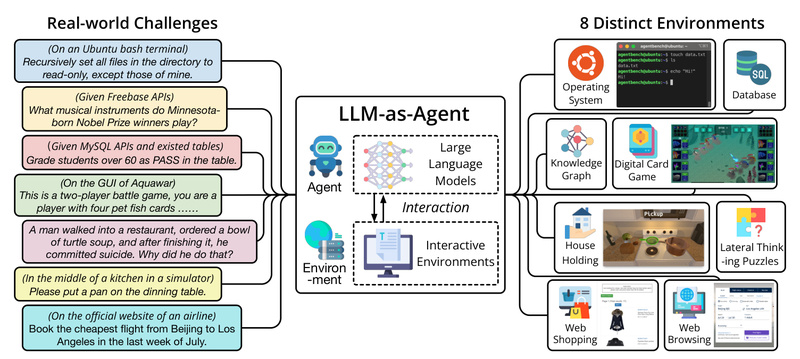
As large language models (LLMs) increasingly power autonomous agents—from customer service bots to system administration tools—a critical question arises: Can…