Training large language models and vision architectures is notoriously slow, unstable, and expensive. Practitioners routinely face diminishing returns from standard…
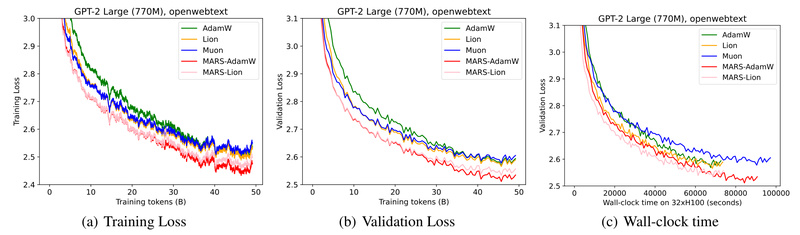
Training large language models and vision architectures is notoriously slow, unstable, and expensive. Practitioners routinely face diminishing returns from standard…