Understanding what happens in videos—especially those capturing everyday human activities—is a core challenge in AI. Most existing video-language models generate…
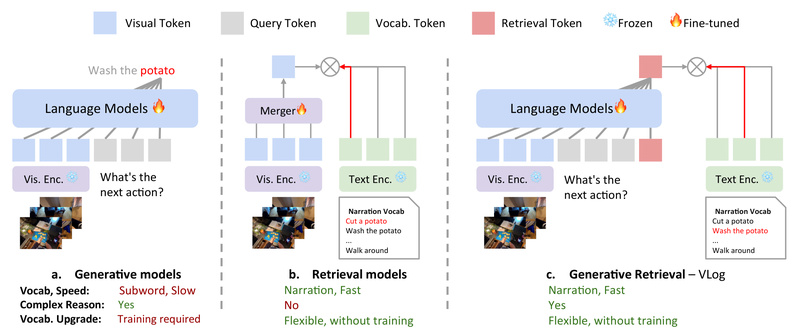
Understanding what happens in videos—especially those capturing everyday human activities—is a core challenge in AI. Most existing video-language models generate…

If you’re evaluating vision-language models for a project that involves both images and videos, you’ve probably faced a frustrating trade-off:…