Imagine deploying a single robot policy that works across different hardware—robotic arms, mobile bases, or even human-inspired setups—without retraining from…
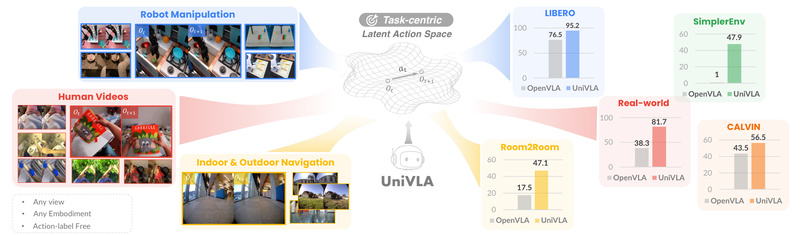
Imagine deploying a single robot policy that works across different hardware—robotic arms, mobile bases, or even human-inspired setups—without retraining from…