Building capable robotic systems that understand vision, language, and action—commonly referred to as Vision-Language-Action (VLA) models—has become a central goal…
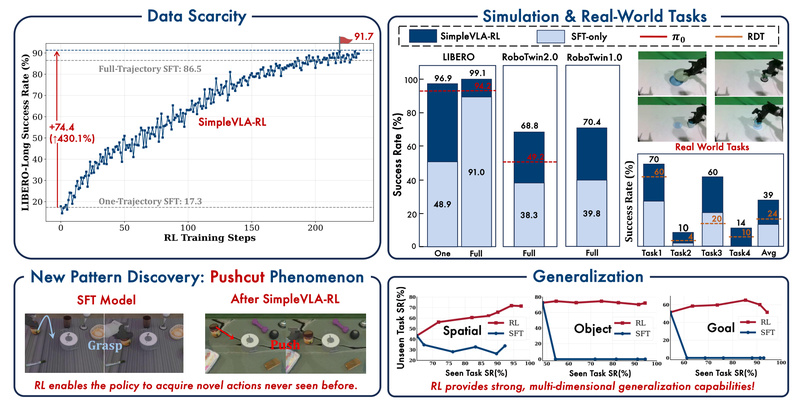
Building capable robotic systems that understand vision, language, and action—commonly referred to as Vision-Language-Action (VLA) models—has become a central goal…
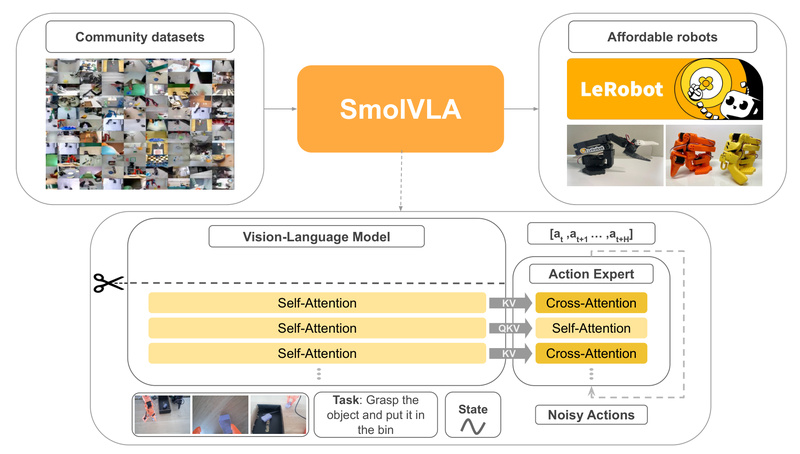
SmolVLA is a compact yet capable Vision-Language-Action (VLA) model designed to bring state-of-the-art robot control within reach of researchers, educators,…
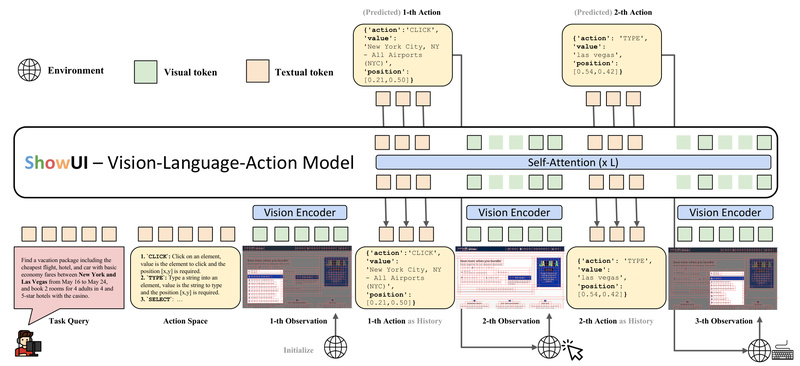
In today’s digital workflows, automating interactions with graphical user interfaces (GUIs)—whether on websites, mobile apps, or desktop software—is a high-value…