In the era of foundation models, CLIP (Contrastive Language–Image Pretraining) has revolutionized how we approach vision-language tasks—especially zero-shot image classification.…
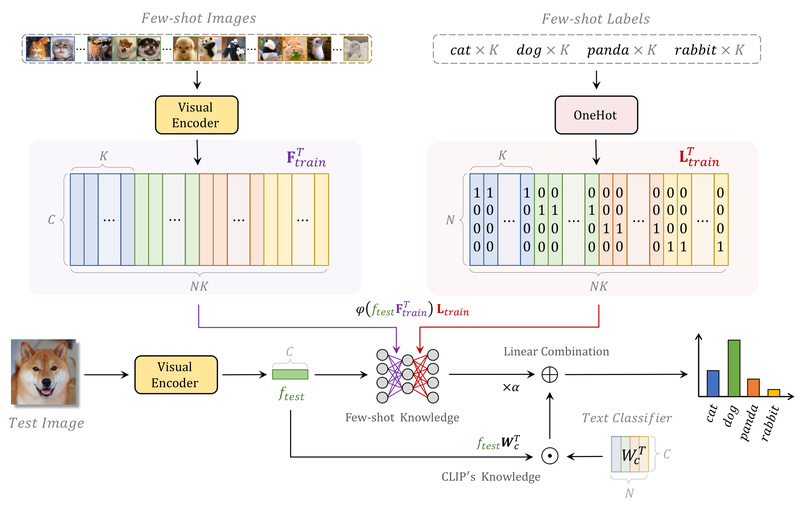
In the era of foundation models, CLIP (Contrastive Language–Image Pretraining) has revolutionized how we approach vision-language tasks—especially zero-shot image classification.…