In an era where multimodal large language models (MLLMs) are rapidly advancing, a critical barrier remains: most high-performing vision-language models…
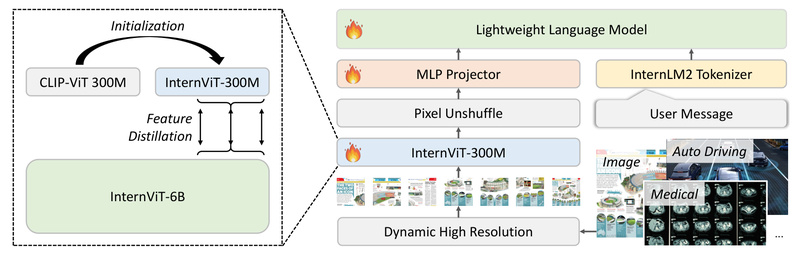
In an era where multimodal large language models (MLLMs) are rapidly advancing, a critical barrier remains: most high-performing vision-language models…
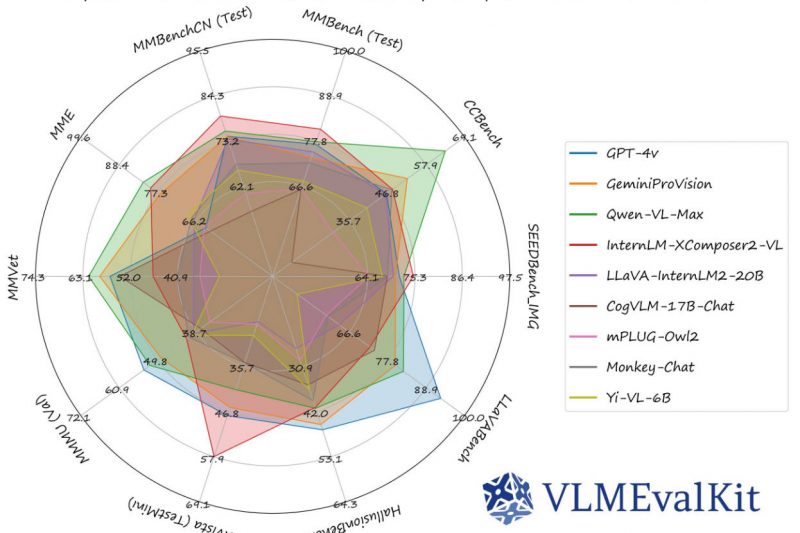
Evaluating large vision-language models (LVLMs) used to be a fragmented, time-consuming chore—juggling dozens of benchmark repositories, writing custom data loaders,…

In today’s AI-driven world, turning unstructured visual data—like scanned invoices, handwritten notes, or multilingual PDFs—into structured, machine-readable formats is a…
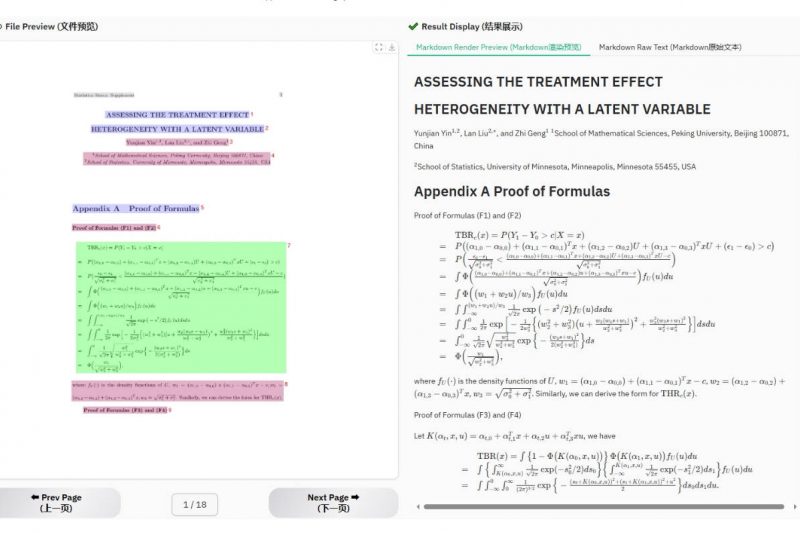
Parsing complex documents—especially those containing tables, mathematical formulas, mixed layouts, or multilingual content—remains a persistent challenge in real-world AI applications.…