Autonomous driving research has long been bottlenecked by the need for massive datasets, expensive compute infrastructure, and proprietary end-to-end frameworks.…
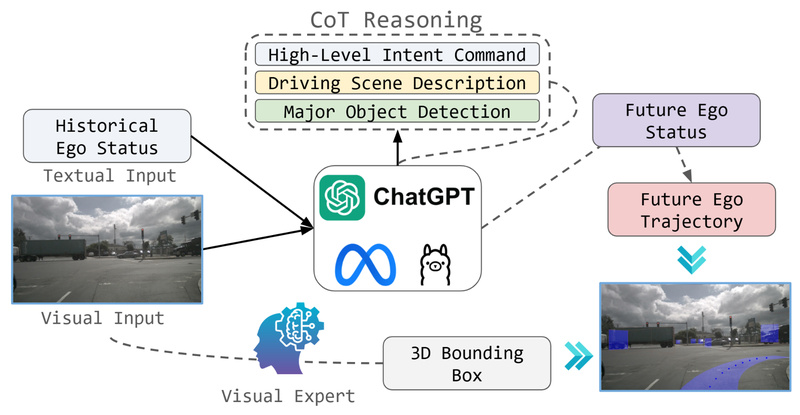
Autonomous driving research has long been bottlenecked by the need for massive datasets, expensive compute infrastructure, and proprietary end-to-end frameworks.…