In today’s AI-driven product landscape, the ability to understand both images and text isn’t just a research novelty—it’s a practical…
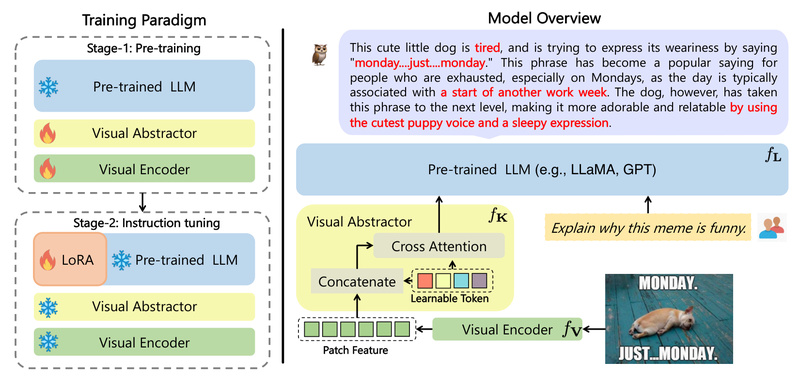
In today’s AI-driven product landscape, the ability to understand both images and text isn’t just a research novelty—it’s a practical…
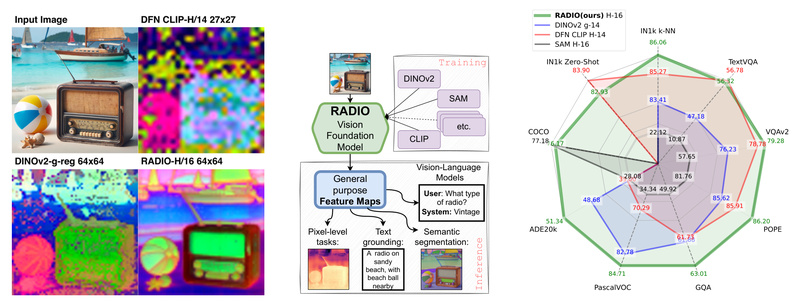
In modern computer vision, practitioners often juggle multiple foundation models—CLIP for vision-language alignment, DINOv2 for dense feature extraction, and SAM…
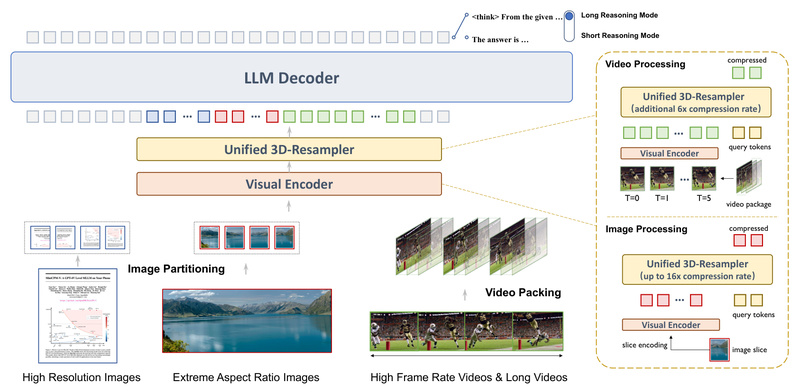
Multimodal Large Language Models (MLLMs) promise to transform how machines understand images, videos, and text—but most top-performing models come with…