DeepSeek-VL2 is an open-source, advanced vision-language model (VLM) built on a Mixture-of-Experts (MoE) architecture, engineered for robust multimodal understanding across…
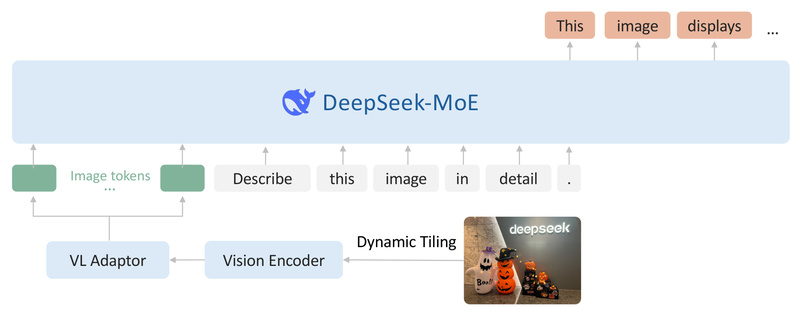
DeepSeek-VL2 is an open-source, advanced vision-language model (VLM) built on a Mixture-of-Experts (MoE) architecture, engineered for robust multimodal understanding across…