Large Multimodal Models (LMMs) like GPT-4V and Gemini promise powerful vision-language understanding—but how well do they actually read text in…

Large Multimodal Models (LMMs) like GPT-4V and Gemini promise powerful vision-language understanding—but how well do they actually read text in…
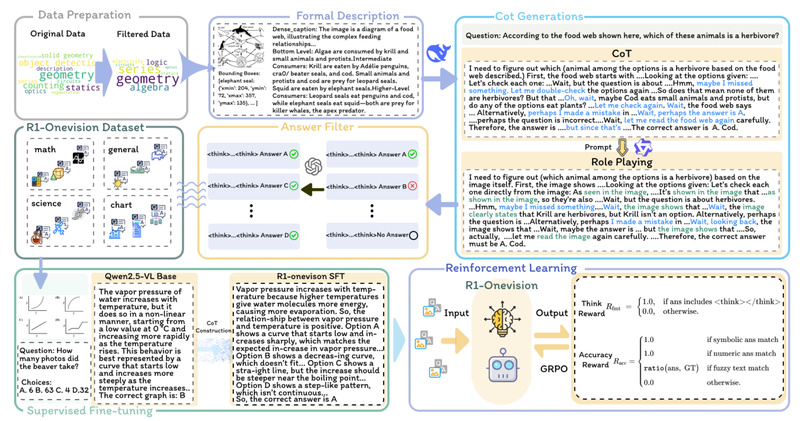
In today’s AI landscape, most multimodal models can describe what’s in an image—but few can reason through it. If your…

As Large Vision-Language Models (LVLMs) grow increasingly capable—and increasingly complex—evaluating their multimodal reasoning, perception, and reliability has become a significant…
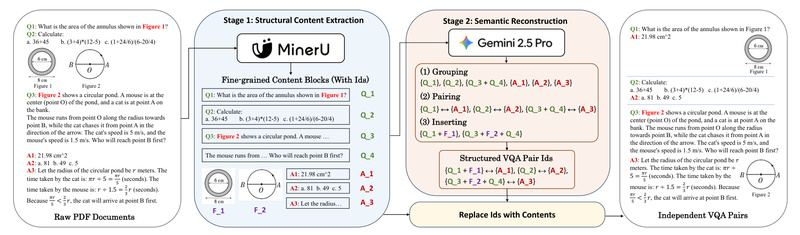
Large Language Models (LLMs) and multimodal systems increasingly demand high-quality, human-authored supervision data—especially for tasks requiring reasoning, visual understanding, and…

In the rapidly evolving landscape of multimodal artificial intelligence, developers and technical decision-makers need models that go beyond basic image…

If you’re evaluating vision-language models for a project that involves both images and videos, you’ve probably faced a frustrating trade-off:…
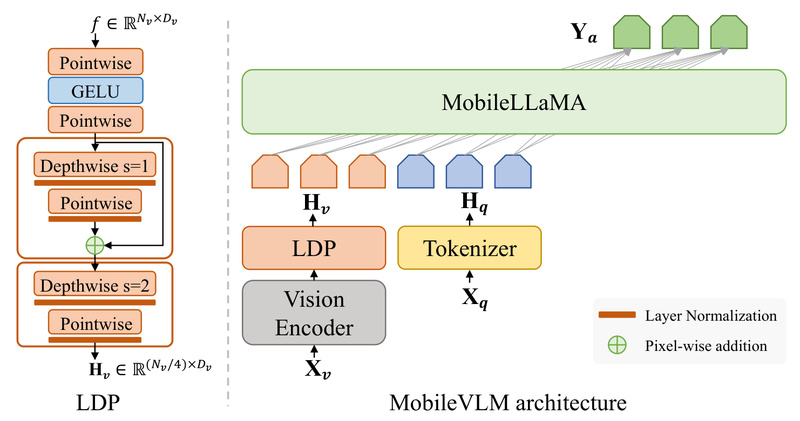
MobileVLM is a purpose-built vision-language model (VLM) engineered from the ground up for on-device deployment on smartphones and edge hardware.…

Imagine asking a computer vision system to “segment the object that makes the woman stand higher” or “show me the…
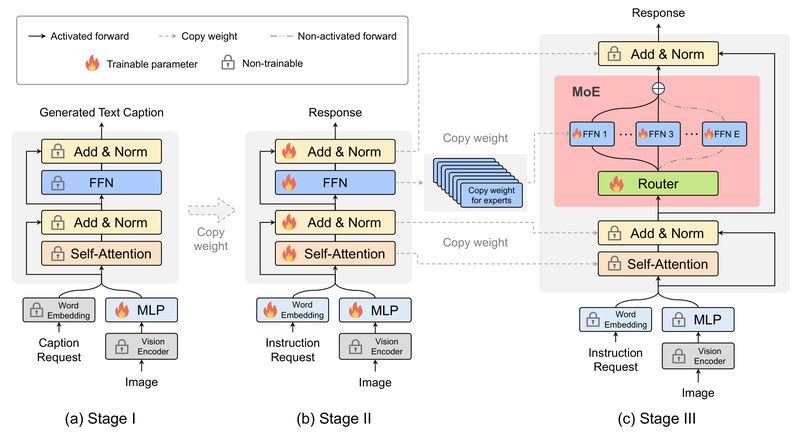
MoE-LLaVA (Mixture of Experts for Large Vision-Language Models) redefines efficiency in multimodal AI by delivering performance that rivals much larger…

Most vision-language models (VLMs) today can describe what’s in an image—but they often falter when asked to reason about it.…