Traditional multimodal large language models (MLLMs) often produce answers without revealing how they got there—especially when dealing with complex questions…
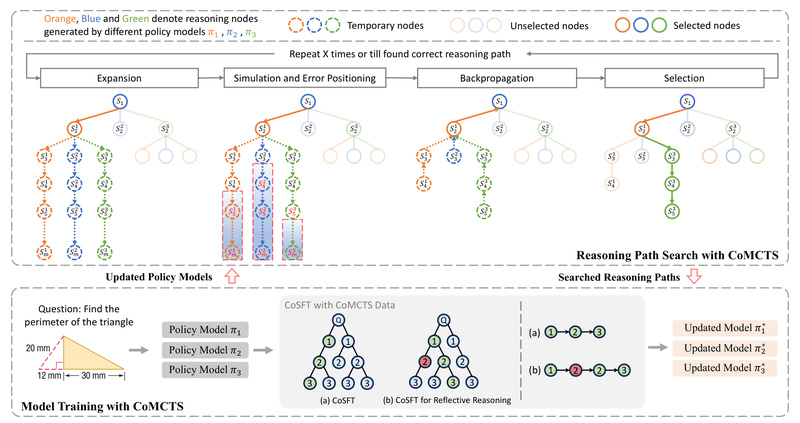
Traditional multimodal large language models (MLLMs) often produce answers without revealing how they got there—especially when dealing with complex questions…
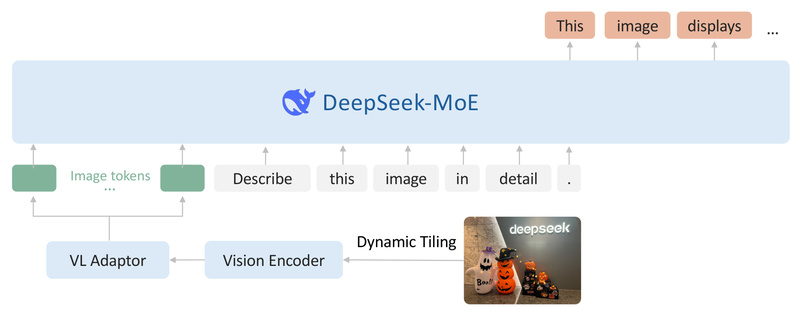
DeepSeek-VL2 is an open-source, advanced vision-language model (VLM) built on a Mixture-of-Experts (MoE) architecture, engineered for robust multimodal understanding across…
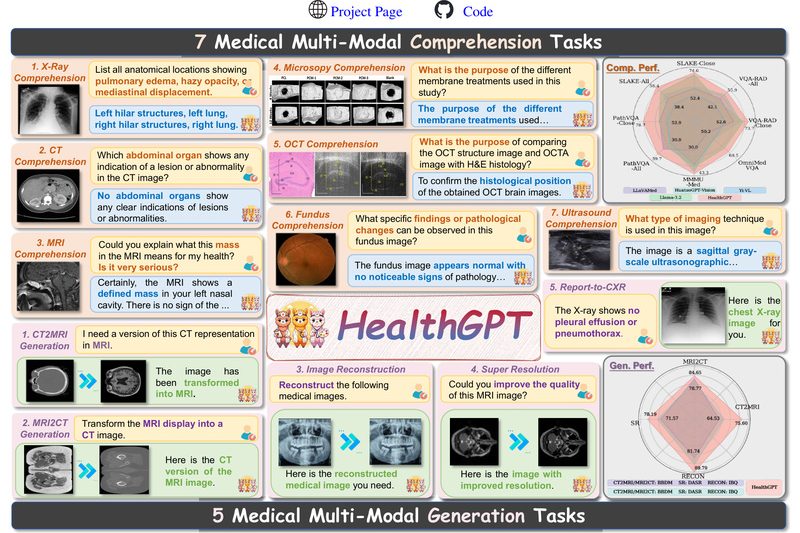
HealthGPT is a cutting-edge Medical Large Vision-Language Model (Med-LVLM) designed to tackle a long-standing challenge in AI for healthcare: the…