When labeled visual data is scarce—think dozens or hundreds of examples per category—traditional supervised fine-tuning (SFT) often falls short. Enter…
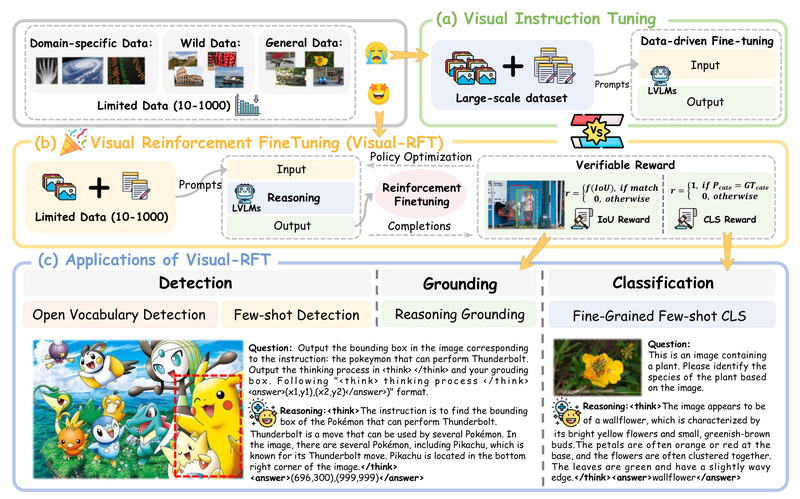
When labeled visual data is scarce—think dozens or hundreds of examples per category—traditional supervised fine-tuning (SFT) often falls short. Enter…