Deploying large language models (LLMs) in production often runs into a hard trade-off: reduce model size and latency through quantization,…
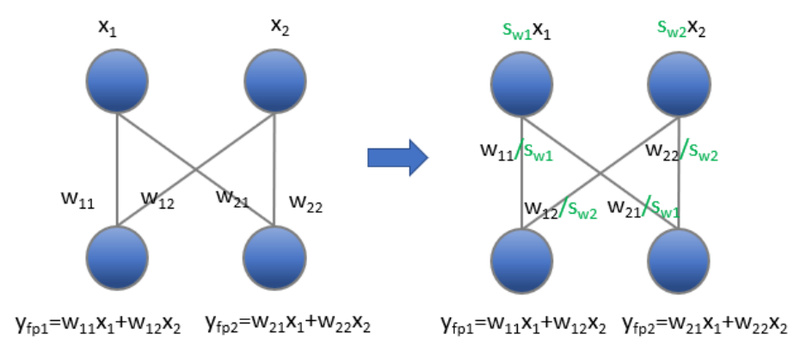
Deploying large language models (LLMs) in production often runs into a hard trade-off: reduce model size and latency through quantization,…