Imagine a single AI model that doesn’t just “see” or “read”—but seamlessly blends images and text in both input and…
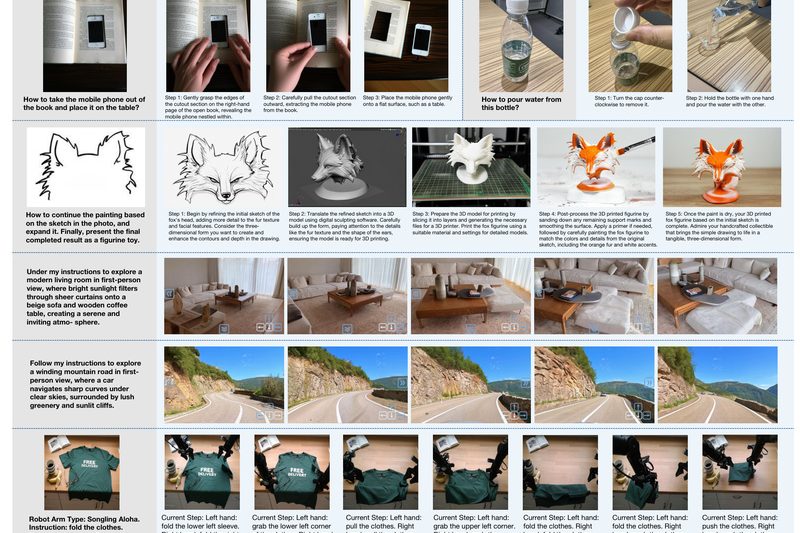
Imagine a single AI model that doesn’t just “see” or “read”—but seamlessly blends images and text in both input and…