Processing Thai text presents unique challenges for developers and data scientists. Unlike English and many other languages, Thai is written…

Processing Thai text presents unique challenges for developers and data scientists. Unlike English and many other languages, Thai is written…
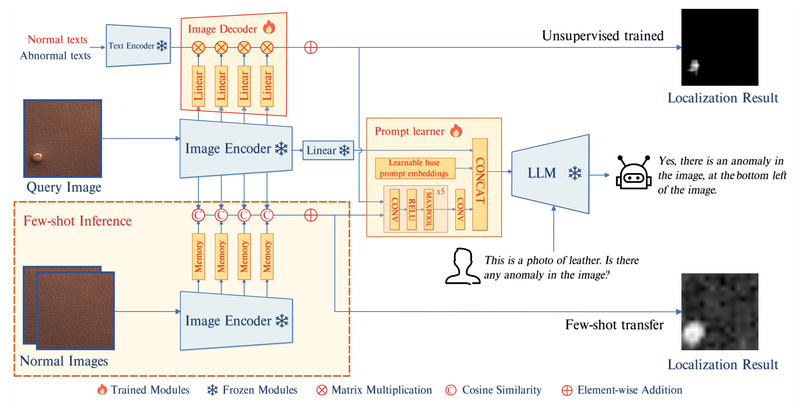
In industrial quality control, detecting defects—like cracks in concrete, scratches on metal, or deformities in packaged goods—is critical. Yet traditional…
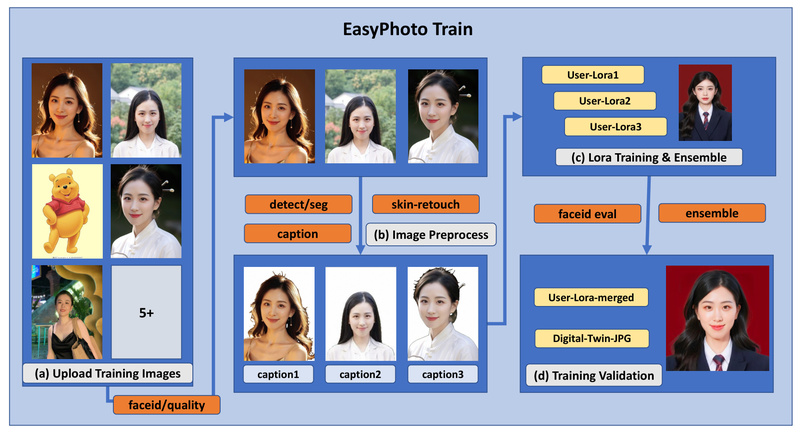
In today’s fast-paced digital world, creating high-quality, personalized photos—whether for professional headshots, marketing campaigns, or custom avatars—often requires photography sessions,…
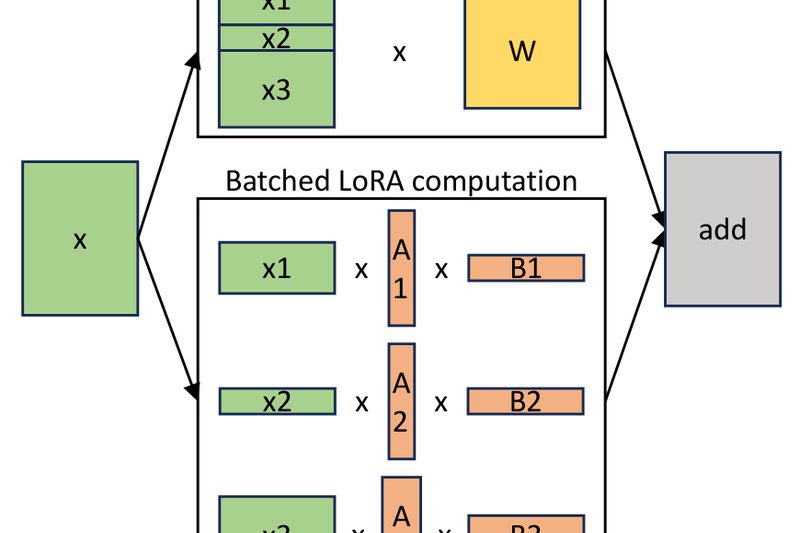
Deploying dozens—or even thousands—of fine-tuned large language models (LLMs) has traditionally been a costly and complex endeavor. Each adapter typically…
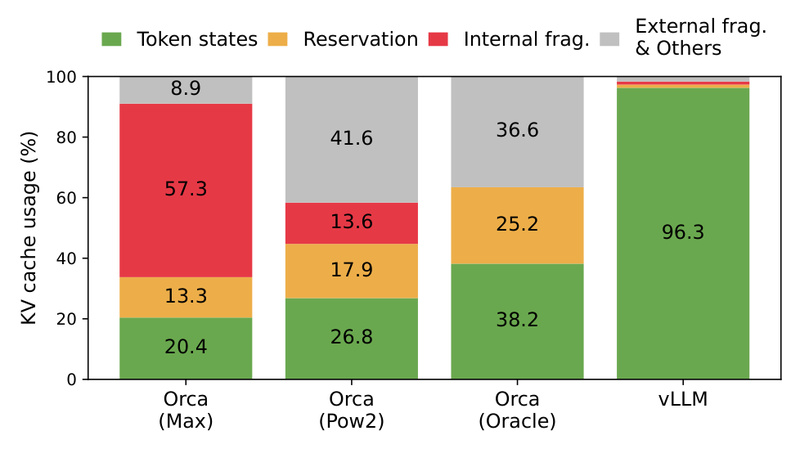
If you’re building or scaling a system that relies on large language models (LLMs)—whether for chatbots, embeddings, multimodal reasoning, or…
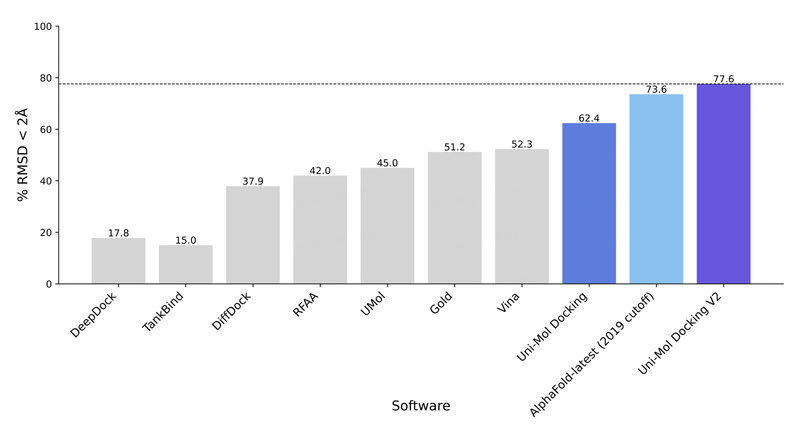
In the rapidly evolving field of computational drug discovery, one of the most persistent challenges is accurately predicting how small…
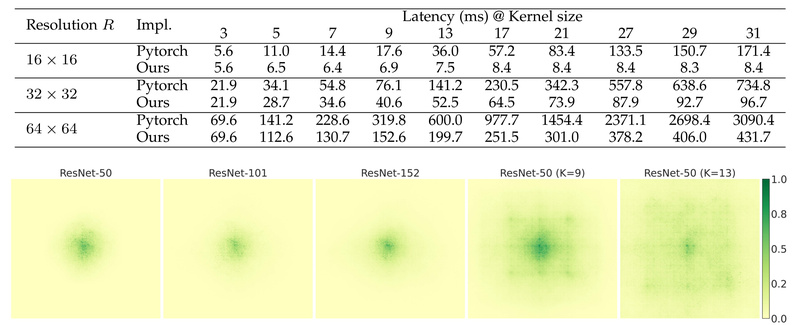
In the era of Vision Transformers and increasingly complex multimodal architectures, convolutional neural networks (ConvNets) have often been written off…

FluxMusic represents a significant step forward in the field of AI-driven audio synthesis—specifically for generating music directly from natural language…

In today’s AI landscape, multimodal systems that understand both images and language are no longer a luxury—they’re a necessity. Yet,…
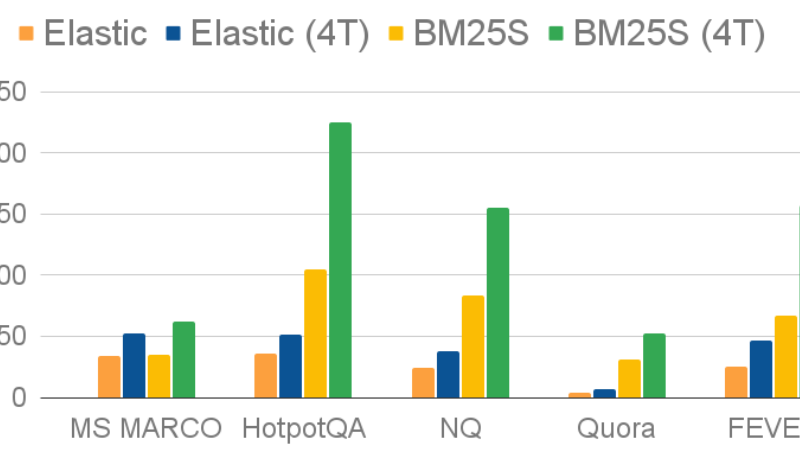
In today’s world of AI-powered search and retrieval, speed, simplicity, and low resource usage are non-negotiable—especially during prototyping, research, or…