If you’re building or scaling large language models (LLMs) and have access to NVIDIA GPU clusters, Megatron-LM—developed by NVIDIA—is one…
If you’re building or scaling large language models (LLMs) and have access to NVIDIA GPU clusters, Megatron-LM—developed by NVIDIA—is one…
In today’s world of intelligent systems—from autonomous robots to immersive AR experiences—depth perception is essential. Yet most cameras only capture…
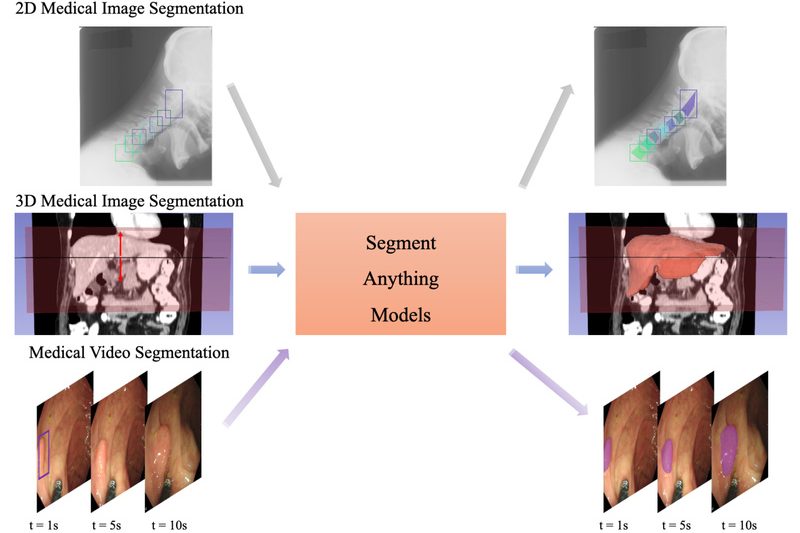
Medical image segmentation—the process of delineating anatomical structures or pathologies in scans like CT, MRI, or ultrasound—is foundational to diagnosis,…
In the landscape of spoken language processing, accurately identifying who is speaking—across recordings, meetings, or voice-based interfaces—remains a critical yet…
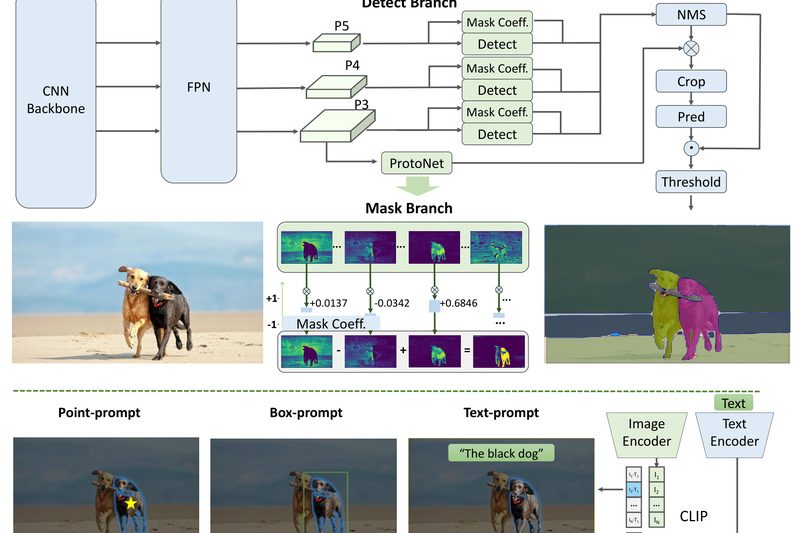
In today’s fast-paced computer vision landscape, high-quality image segmentation is no longer a luxury—it’s a necessity. Yet, despite the groundbreaking…
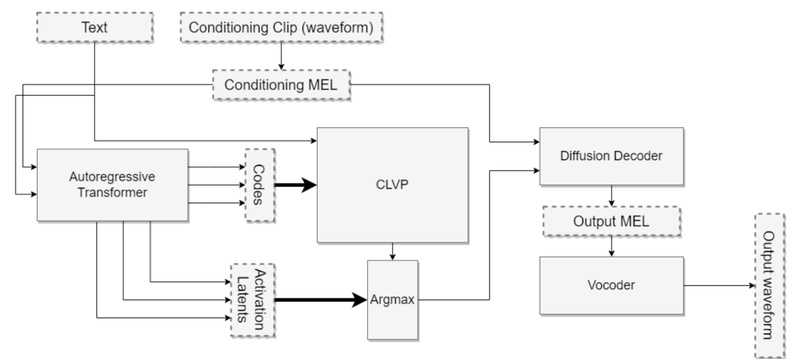
Tortoise-TTS is an open-source text-to-speech (TTS) system designed for one core purpose: generating expressive, natural-sounding speech with strong multi-voice capabilities.…

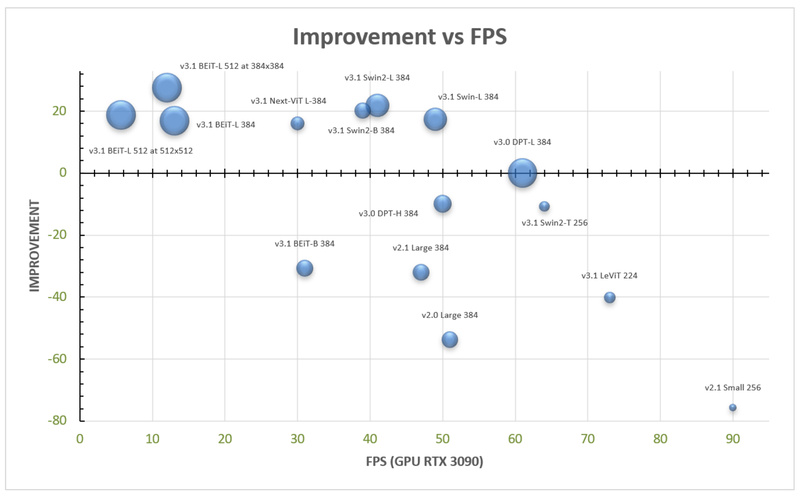
Image super-resolution (SR) remains a critical capability across computer vision applications—from upscaling smartphone photos to enhancing AI-generated content (AIGC). However,…
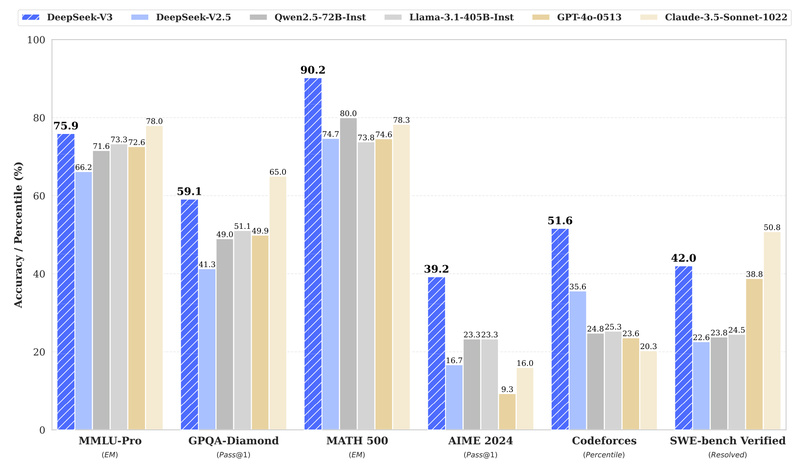
For technical decision-makers evaluating large language models (LLMs) for real-world applications, balancing raw capability, inference cost, training efficiency, and deployment…

If you’re working on a project that requires a capable language model—but lack the GPU budget, time, or infrastructure for…

Imagine you have access to a powerful pre-trained vision-language model like CLIP—capable of understanding both images and text—but you need…