In an increasingly multilingual and interconnected world, spoken language translation (SLT) has moved beyond academic curiosity to become a critical…

In an increasingly multilingual and interconnected world, spoken language translation (SLT) has moved beyond academic curiosity to become a critical…
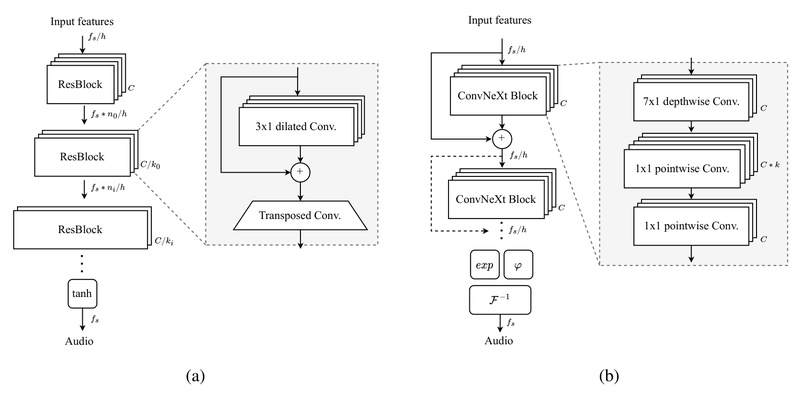
If you’re building or evaluating text-to-speech (TTS), voice cloning, or generative audio systems, the choice of neural vocoder can make…
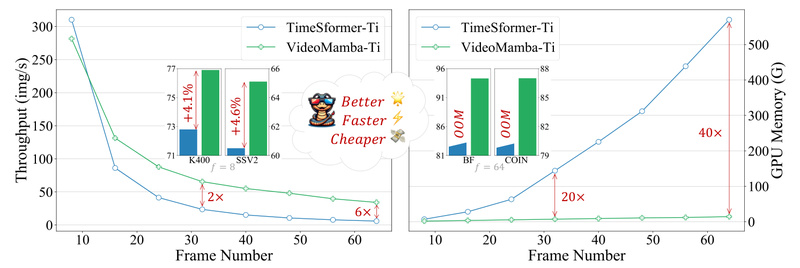
Video understanding has long been bottlenecked by two competing demands: capturing fine-grained local motion while simultaneously modeling long-range temporal dependencies.…
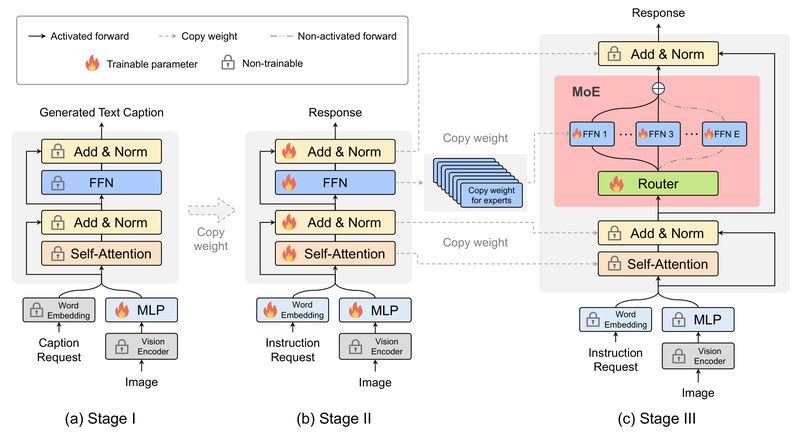
MoE-LLaVA (Mixture of Experts for Large Vision-Language Models) redefines efficiency in multimodal AI by delivering performance that rivals much larger…

Developing general-purpose robots that can navigate, interact, and manipulate in real-world urban environments remains one of the most demanding challenges…
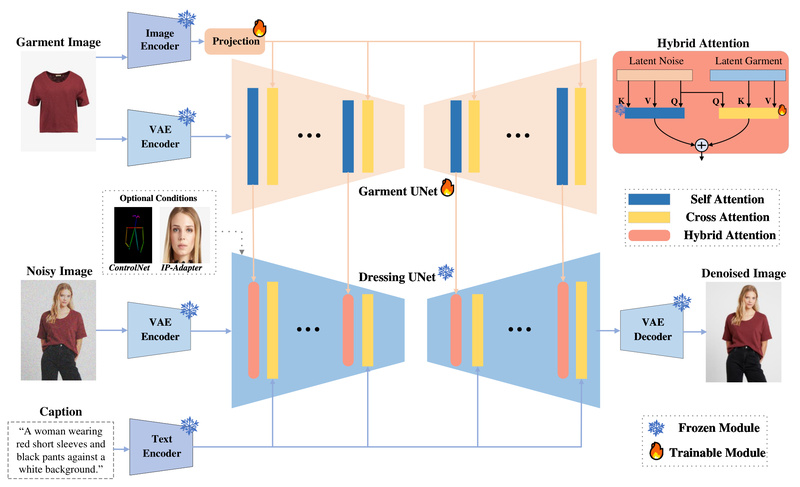
Online fashion retailers, digital content studios, and marketing teams increasingly rely on realistic human imagery to showcase garments—but traditional virtual…
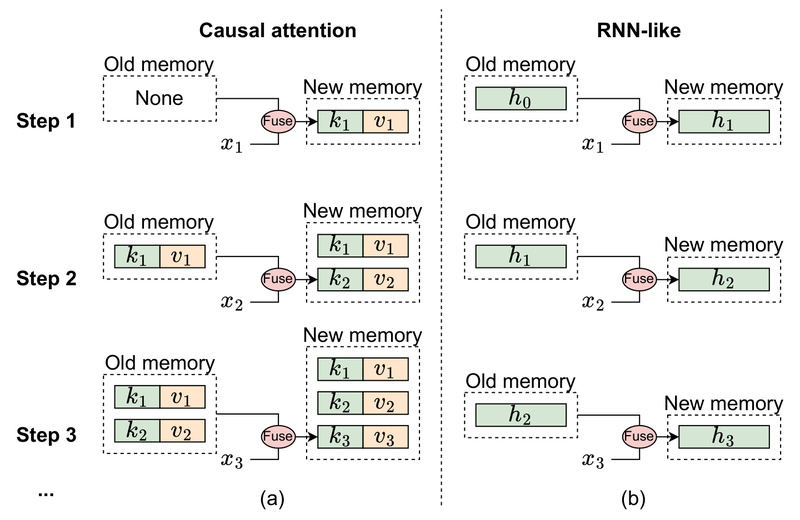
The vision community has recently seen a surge in adopting sequence modeling architectures—especially Mamba—for image tasks. Inspired by its linear…
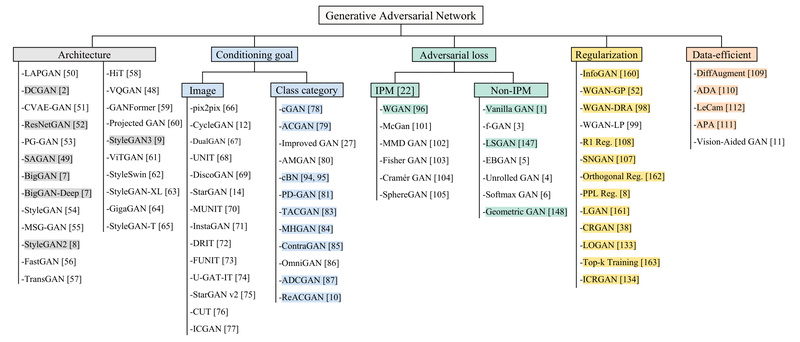
Generative Adversarial Networks (GANs) have long been at the forefront of realistic image synthesis—but using them effectively in research or…
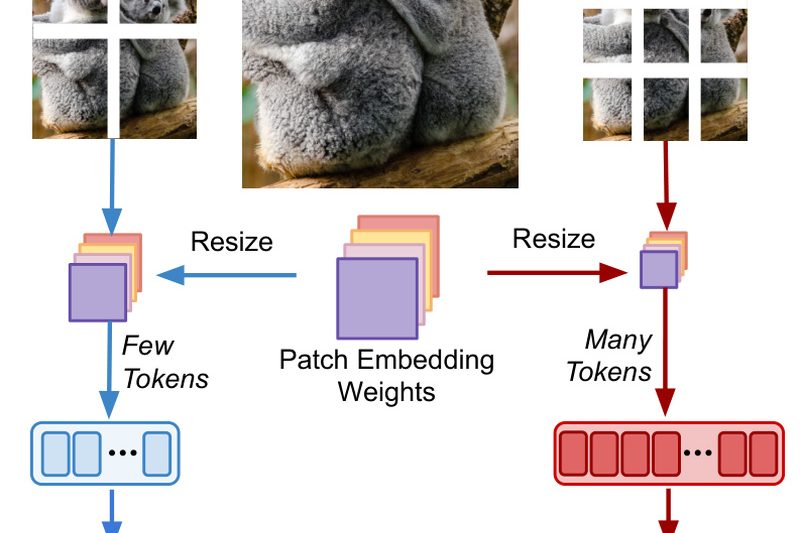
Vision Transformers (ViTs) have become a cornerstone of modern computer vision, offering strong performance across a wide range of tasks.…
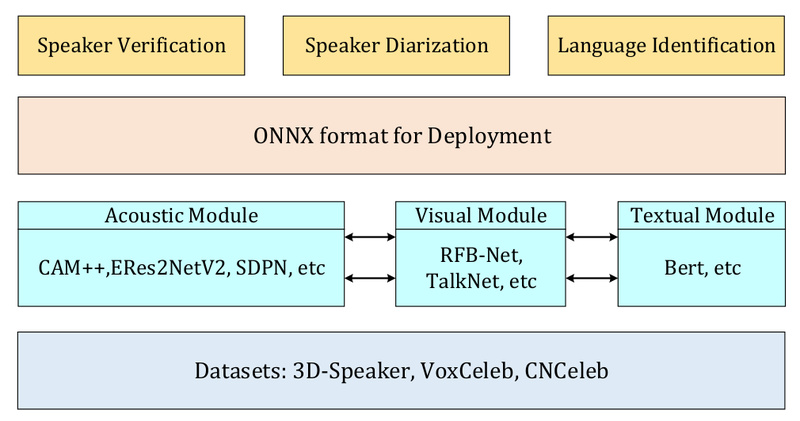
Speaker analysis—whether for verifying identity, recognizing who’s speaking, or separating voices in a multi-person conversation—is a fundamental task in speech…