Visual-Inertial Navigation Systems (VINS) are critical for applications like drones, robotics, and augmented reality, where precise real-time localization is required…
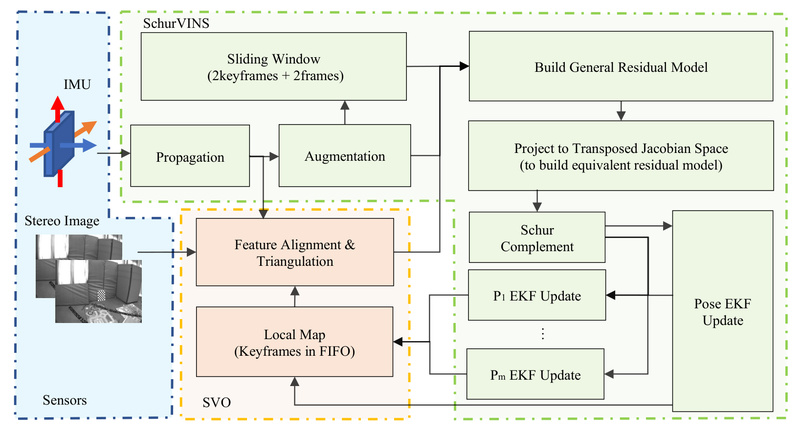
Visual-Inertial Navigation Systems (VINS) are critical for applications like drones, robotics, and augmented reality, where precise real-time localization is required…

Developing effective, task-oriented agents powered by large language models (LLMs) has become a priority for researchers and developers alike. However,…
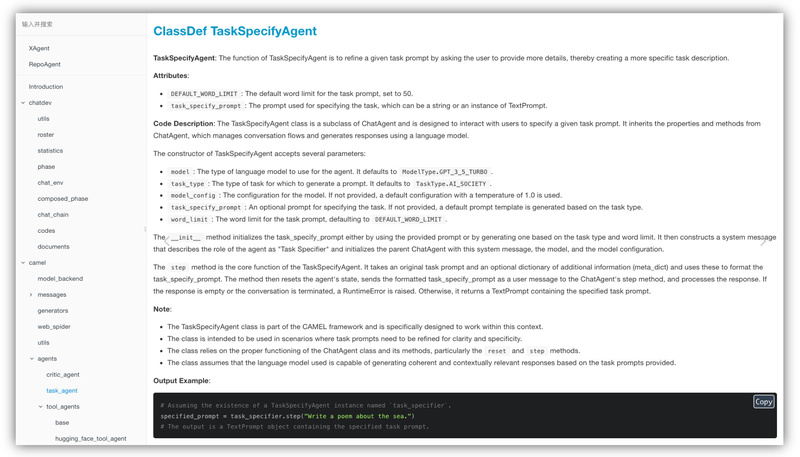
Keeping code documentation up to date is one of the most universally acknowledged yet consistently neglected tasks in software development.…

Video generation using diffusion transformers (DiTs) has reached remarkable visual fidelity—but at a steep computational cost. The quadratic complexity of…

Recommender systems are foundational to modern digital experiences—from streaming platforms to e-commerce—but they face a persistent challenge: user interaction data…

In real-world computer vision systems—whether for autonomous vehicles, remote sensing, or robotic inspection—images rarely come from a single type of…
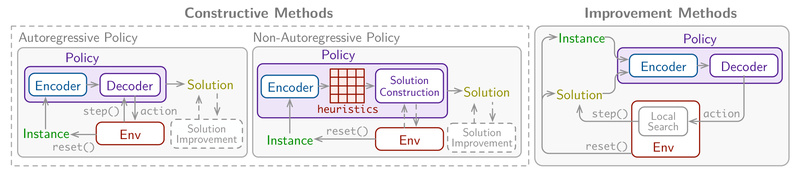
Combinatorial optimization (CO) lies at the heart of countless real-world challenges—from vehicle routing and job scheduling to chip design and…
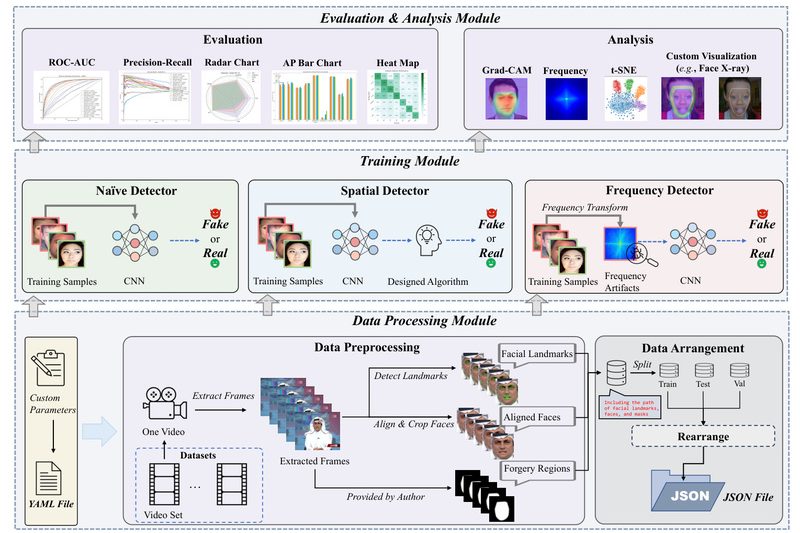
Deepfake detection is rapidly becoming a critical component of digital trust and media integrity. Yet despite growing interest and investment,…

Synthetic Aperture Radar (SAR) imaging offers a unique advantage: it works reliably in all weather conditions, day or night, making…
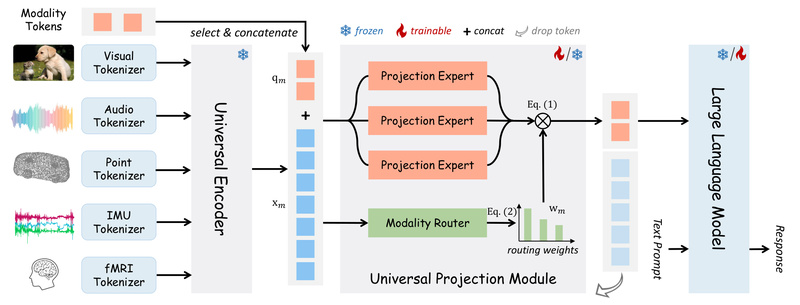
Multimodal AI is no longer just about images and text—it’s about seamlessly blending diverse data streams like audio, video, 3D…