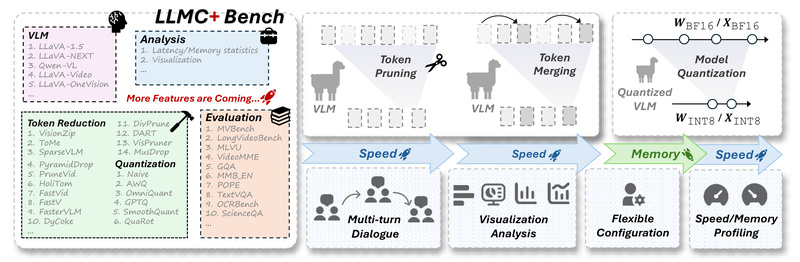
Deploying large vision-language models (VLMs) and large language models (LLMs) in real-world applications is often bottlenecked by their massive size, high memory consumption, and slow inference speeds. These challenges become even more pronounced when handling long visual token sequences in multimodal tasks or running massive Mixture-of-Experts (MoE) models with hundreds of billions of parameters. Enter LLMC+—a versatile, training-free, plug-and-play compression toolkit that enables practitioners to significantly reduce model size and computational cost while preserving performance.
Originally known as LLMC and now rebranded as LightCompress, LLMC+ provides a unified framework for evaluating and applying state-of-the-art compression techniques—including token reduction, quantization, and pruning—across a wide range of modern AI models. Whether you’re working with Llama-3.2-Vision, Qwen2-VL, DeepSeek-R1 (671B), or standard LLMs like Mistral and LLaMA, LLMC+ offers a streamlined path to efficient deployment without the need for retraining.
Why LLMC+ Matters: Solving Real-World Deployment Bottlenecks
Many project teams face practical constraints: limited GPU memory, latency-sensitive user experiences, or tight hardware budgets. Large VLMs, while powerful, often demand multiple high-end GPUs just to load, making them impractical for edge deployment or cost-efficient cloud inference. LLMC+ directly tackles these pain points by offering training-free compression that can be applied post-hoc to pre-trained models.
Unlike ad-hoc compression scripts or fragmented tooling, LLMC+ is built as a benchmark-aware platform. It doesn’t just compress—it helps you understand which techniques work best under which conditions. This is especially critical for multimodal systems, where visual token redundancy behaves differently across spatial and temporal dimensions, and where naive compression can severely degrade performance in multi-turn dialogues or detail-sensitive tasks.
What Makes LLMC+ Unique: Fair, Modular, and Comprehensive
LLMC+ stands out through three core design principles:
1. Modular, Plug-and-Play Architecture
Compression methods in LLMC+ are decomposed into interchangeable components. This allows fair comparison across algorithms—whether you’re evaluating ToMe vs. FastV for token reduction or AWQ vs. SmoothQuant for quantization. The modular setup ensures that differences in performance stem from the algorithm itself, not implementation quirks.
2. Broad Algorithm and Model Coverage
LLMC+ supports over 20 compression algorithms spanning:
- Token reduction: ToMe, FastV, SparseVLM, VisionZip, and more
- Quantization: AWQ, GPTQ, SmoothQuant, OmniQuant, QuaRot, SpinQuant, and floating-point formats like FP8 (E4M3/E5M2)
- Pruning: Wanda, magnitude-based sparsification
It also covers five major VLM families (e.g., LLaMA-Vision, Qwen2-VL, InternVL2) and a wide array of LLMs, including MoE architectures like DeepSeekv3 and DeepSeek-R1 (671B parameters). This breadth enables systematic experimentation across model types and compression strategies.
3. Realistic Evaluation Beyond Toy Benchmarks
LLMC+ moves beyond single-turn, image-captioning-style evaluations. Its benchmarking protocol includes multi-turn dialogue scenarios and fine-grained visual understanding tasks, revealing that token compression methods often falter in complex interactions—a crucial insight for production systems.
Ideal Use Cases: When Should You Reach for LLMC+?
LLMC+ shines in scenarios where efficiency and deployability are non-negotiable:
- Deploying VLMs on limited hardware: Compress LLaMA-3.2-Vision or Qwen2-VL to fit within a single 80GB GPU.
- Running massive MoE models: Quantize DeepSeek-R1 (671B) with INT4/INT8 weights and run PPL evaluation on one A100/H100.
- Preparing models for inference backends: Export truly quantized models (not just fake quantization) compatible with vLLM, SGLang, LightLLM, MLC-LLM, and AutoAWQ for accelerated, memory-efficient serving.
- Rapid prototyping and ablation studies: Test combinations of token reduction + quantization to achieve extreme compression with minimal accuracy drop—something LLMC+’s benchmarking reveals is often possible.
Getting Started: A Practitioner-Friendly Workflow
LLMC+ is designed for ease of adoption:
- Pull the Docker image (available on Docker Hub or Alibaba Cloud for users in mainland China)
- Choose a model from the extensive supported list—or add your own by extending
llmc/models/*.py - Select a compression method (e.g., AWQ for quantization, ToMe for token merging)
- Apply compression with a single config file—no training or fine-tuning required
- Export the compressed model in a backend-ready format (e.g., LightLLM, vLLM)
Best-practice configurations are provided for common model-algorithm pairs, and evaluation is supported via modified versions of lm-evaluation-harness and OpenCompass. This means you can validate performance immediately after compression.
Limitations and Considerations
While LLMC+ offers powerful capabilities, users should be aware of current limitations:
- Token reduction methods (e.g., ToMe, FastV) may underperform in detail-sensitive tasks (e.g., medical imaging analysis) or multi-turn conversational VLMs, as highlighted in the LLMC+ benchmark.
- Not all models are natively supported, though the framework is extensible—adding a new model typically requires implementing a model-specific adapter.
- Extreme compression (e.g., INT4 quantization + aggressive token pruning) will always involve trade-offs. LLMC+ helps you measure these trade-offs systematically but doesn’t eliminate them.
Summary
LLMC+ (now LightCompress) fills a critical gap in the AI deployment pipeline by providing a standardized, training-free, and extensible toolkit for compressing both LLMs and VLMs. Its emphasis on fair benchmarking, broad algorithm support, and real-world evaluation makes it an invaluable resource for engineers, researchers, and technical decision-makers looking to deploy powerful models efficiently—without compromising on scientific rigor or practical usability. If you’re facing memory, latency, or cost barriers with large multimodal models, LLMC+ offers a pragmatic, well-documented path forward.