Large language models (LLMs) are powerful, but adapting them to specific tasks often demands significant effort: collecting labeled data, tuning hyperparameters, and running expensive fine-tuning jobs. What if you could skip all that—and instead generate a high-performing adapter for your LLM using nothing but a clear sentence describing your task?
That’s exactly what Text-to-LoRA (T2L) delivers. Developed by SakanaAI, T2L is a hypernetwork that constructs task-specific LoRA (Low-Rank Adaptation) modules in a single forward pass, using only a natural language description. No datasets. No training loops. No GPU clusters. Just a description—and within seconds, you get a LoRA adapter ready to plug into your base model.
This approach dramatically lowers the barrier to customizing foundation models, enabling rapid iteration, zero-shot generalization to new tasks, and on-demand specialization without ML expertise.
How Text-to-LoRA Works
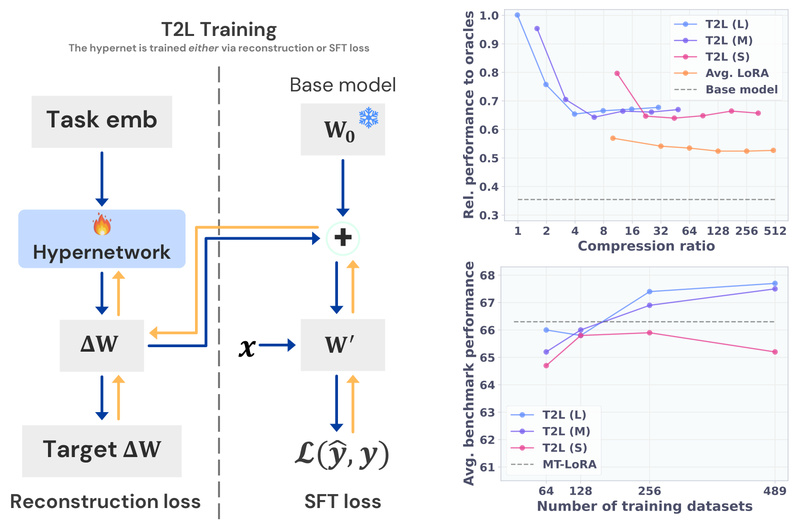
At its core, T2L treats LoRA generation as a prediction problem. It’s trained on a diverse set of pre-existing LoRA adapters (e.g., for GSM8K, ARC, BoolQ) and learns to map task descriptions—like “This task tests mathematical reasoning through word problems”—to the corresponding low-rank weight updates that would normally require full fine-tuning.
Once trained, T2L acts as a “adapter factory”:
- You provide a textual task description.
- T2L outputs a complete LoRA checkpoint compatible with standard LLM inference pipelines.
- You attach the generated LoRA to your base model (e.g., Llama-3.1-8B or Gemma-2-2B) and run inference immediately.
Critically, T2L isn’t just interpolating between known tasks—it generalizes to unseen tasks, compressing the knowledge of hundreds of adapters into a single, efficient model. Experiments show that T2L-generated LoRAs frequently match or approach the performance of hand-tuned, task-specific LoRAs, even on benchmarks they weren’t explicitly trained on.
Key Advantages Over Traditional Fine-Tuning
1. Zero Data Requirement
Traditional LoRA fine-tuning needs a curated dataset for each new task. T2L needs none. This is transformative for niche domains where labeled data is scarce or expensive to produce.
2. Instant Adaptation
Generating a LoRA with T2L takes seconds, not hours or days. This enables real-time experimentation—try five different task formulations in the time it would normally take to launch one training job.
3. Minimal Compute Overhead
T2L itself is lightweight. While you’ll need a GPU (≥16GB VRAM recommended) to run both T2L and the base LLM simultaneously during generation, once the LoRA is created, it can be deployed like any standard adapter—with negligible memory or latency cost during inference.
4. Democratizes LLM Customization
You no longer need deep ML knowledge to specialize an LLM. A product manager, educator, or support engineer can describe a task in plain English and get a working adapter—bridging the gap between domain experts and model deployment.
Ideal Use Cases for Practitioners
T2L excels in scenarios where speed, flexibility, and accessibility matter more than pixel-perfect optimization:
- Rapid prototyping: Test whether a new NLP task is viable before investing in data collection.
- Internal tooling: Customize an LLM for company-specific jargon or workflows without maintaining a fine-tuning pipeline.
- Education & research: Explore how task framing affects model behavior by generating multiple LoRAs from slightly varied descriptions.
- Edge or low-resource deployment: Pre-generate a LoRA offline using T2L, then deploy the lightweight adapter on constrained devices.
For example, a customer support team could generate a LoRA that “answers questions about return policies using empathetic language”—without ever labeling a single support ticket.
Getting Started: A Practical Workflow
Using T2L is designed to be straightforward for engineers and technical decision-makers:
-
Install dependencies using
uv(a modern Python package manager):git clone https://github.com/SakanaAI/text-to-lora.git cd text-to-lora uv sync
-
Download a pre-trained T2L checkpoint (e.g., for Llama-3.1-8B or Gemma-2-2B):
uv run huggingface-cli download SakanaAI/text-to-lora --local-dir . --include "trained_t2l/*"
-
Generate a LoRA from a task description via CLI:
uv run python scripts/generate_lora.py trained_t2l/llama_8b_t2l "This task evaluates logical reasoning in legal scenarios."
The script outputs a path to your new LoRA adapter.
-
Evaluate or deploy the adapter:
uv run python scripts/run_eval.py --model-dir meta-llama/Llama-3.1-8B-Instruct --lora-dirs ./generated_lora_12345 --tasks gsm8k
For interactive use, a Web UI is also available to generate and test LoRAs through a browser-based interface.
Current Limitations and Practical Considerations
While powerful, T2L has realistic constraints:
- Hardware requirements: Running T2L alongside a 7B–8B LLM requires a GPU with >16GB VRAM. Smaller models like Gemma-2-2B may work on 12GB cards.
- Non-determinism: Due to internals in vLLM and other inference engines, minor score variance can occur across evaluation runs—even with fixed seeds. However, relative performance trends remain consistent.
- Description quality matters: T2L performs best with clear, aligned task descriptions (examples are provided in the
tasks/directory). Random or vague prompts still produce functional LoRAs but with reduced effectiveness.
Importantly, T2L isn’t meant to replace fine-tuning in high-stakes, production-critical scenarios where every accuracy point counts. Instead, it’s a strategic tool for exploration, agility, and accessibility.
Summary
Text-to-LoRA reimagines model adaptation as a language-driven process, not a data-driven one. By generating high-quality LoRA adapters from natural language alone, it eliminates the biggest bottlenecks in LLM customization: data curation, training time, and ML expertise.
For technical leaders evaluating efficient, scalable ways to specialize foundation models, T2L offers a compelling trade-off: near-instant adaptation, strong empirical performance, and dramatically lower resource requirements. In a world where agility is competitive advantage, being able to say “adapt my model to do X”—and having it happen seconds later—is not just convenient. It’s transformative.