If you’re evaluating next-generation code generation tools, you’ve likely worked with autoregressive (AR) large language models—systems that build code one token at a time, left to right. But what if your model could plan, revise, and refine an entire function holistically, like a human developer reviewing and editing a draft? That’s the core promise of DiffuCoder, a 7B-parameter diffusion-based large language model (dLLM) purpose-built for code.
Unlike traditional AR models, DiffuCoder leverages a masked diffusion framework: it starts with a noisy (masked) version of a code snippet and iteratively denoises it over multiple steps. This architecture enables global reasoning and structural awareness—critical advantages when generating syntactically correct, logically sound functions from docstrings or partial prompts. Developed by Apple’s machine learning team, DiffuCoder isn’t just another code LLM; it’s a rethinking of how code should be generated.
How DiffuCoder Rethinks Code Generation
Breaking Free from Left-to-Right Generation
Most code LLMs are autoregressive by design: they predict the next token based only on previous ones. This forces a rigid, sequential workflow that struggles with long-range dependencies—like matching opening and closing brackets across dozens of lines or ensuring variable names stay consistent.
DiffuCoder, by contrast, operates on the entire sequence at once during each denoising step. It doesn’t “write” code from start to finish; it refines a rough sketch into a complete solution. This allows it to:
- Adjust early decisions based on later context
- Fix structural errors mid-generation
- Maintain better consistency in naming, typing, and control flow
Critically, DiffuCoder isn’t fully non-causal—it can exhibit left-to-right tendencies (especially after pretraining), but it’s not bound to them. As the authors show, it dynamically chooses how “autoregressive” to be based on context and sampling settings.
Temperature Controls Both What and When
In AR models, raising the sampling temperature increases lexical diversity—you get different tokens. In DiffuCoder, temperature controls something more profound: generation order diversity.
Higher temperatures don’t just yield different tokens—they lead to different sequences of refinement. One run might fill in loop bodies before function signatures; another might prioritize return statements first. This creates a richer exploration space, which proves especially valuable during reinforcement learning (RL) training.
Coupled-GRPO: A Smarter Way to Train Diffusion Code Models
One of DiffuCoder’s breakthroughs is Coupled-GRPO, a novel RL method designed specifically for diffusion models. Traditional RL for dLLMs suffers from high variance because reward signals are computed only on masked positions—many tokens get no learning signal.
Coupled-GRPO solves this with an elegant trick: for each training example, it samples two complementary masks that together cover the full target sequence. Every token is unmasked in exactly one of the two denoising passes, guaranteeing:
- Every token contributes to the loss
- Each token is evaluated in a realistic partially-masked context
- Training remains efficient (only ~2× compute overhead)
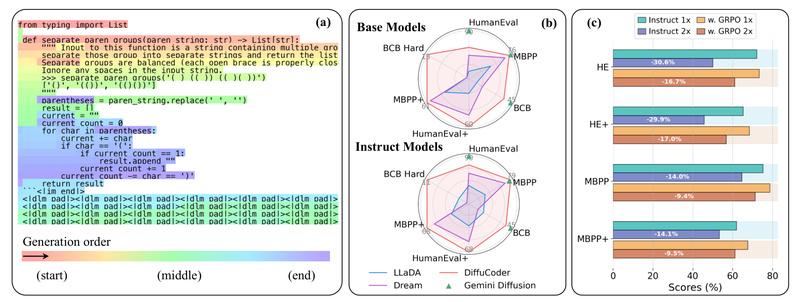
The result? A +4.4% improvement on EvalPlus, a rigorous benchmark for code correctness. More importantly, the model learns to rely less on autoregressive bias, unlocking more of diffusion’s native potential.
Ideal Use Cases for DiffuCoder
DiffuCoder shines where global structure and iterative refinement matter more than raw speed:
1. Function Completion from Docstrings
Given a function signature and a docstring (e.g., HumanEval tasks), DiffuCoder generates complete, runnable implementations that respect type hints and behavior specs. Its ability to “see” the whole problem at once leads to fewer logic errors.
2. Chat-Based Coding Assistants
The instruction-tuned variant (DiffuCoder-7B-cpGRPO) responds to natural language prompts like “Write a function to find shared elements from two lists.” It returns not just code, but formatted, explanatory responses—ideal for interactive development environments.
3. High-Correctness Code Synthesis
When correctness trumps latency (e.g., in research, education, or safety-critical tooling), DiffuCoder’s iterative refinement often outperforms AR baselines on pass@1 metrics, as demonstrated on EvalPlus and MBPP.
Getting Started: Simple Integration for Developers
DiffuCoder models are available on Hugging Face and integrate cleanly with standard transformers workflows:
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained("apple/DiffuCoder-7B-Base", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("apple/DiffuCoder-7B-Base", trust_remote_code=True)
Key inference parameters:
TOKEN_PER_STEP: Controls the speed/quality trade-off. Lower values (e.g., 1) mean more denoising steps → higher quality but slower. Higher values speed up generation at the cost of refinement.temperature: Affects both token choice and generation order—use 0.2–0.4 for reliable outputs.
Both base and instruction-tuned variants support .diffusion_generate(), a drop-in replacement for .generate() that handles the diffusion loop internally.
Limitations and Practical Considerations
While promising, DiffuCoder isn’t a drop-in replacement for all AR code models:
- Hardware requirements: Inference currently requires CUDA (no CPU or Apple Silicon support yet). MLX integration is in progress but not ready.
- Speed: At high quality settings (low
TOKEN_PER_STEP), it’s slower than AR models like CodeLlama. Best suited for tasks where correctness > latency. - Training complexity: Fine-tuning with Coupled-GRPO requires an E2B sandbox for code execution and reward computation—non-trivial to set up outside research environments.
- Active development: The codebase builds on Open-R1 and is evolving; expect changes as the team scales to 14B models.
Summary
DiffuCoder represents a meaningful shift in code generation: instead of predicting tokens sequentially, it refines code holistically. This enables better structural awareness, more flexible generation patterns, and—thanks to Coupled-GRPO—state-of-the-art performance on correctness benchmarks.
If your project demands high-fidelity code synthesis, benefits from iterative refinement, or explores alternatives to autoregressive paradigms, DiffuCoder is worth evaluating. With Hugging Face support and a clean API, integration is straightforward for teams already using transformers. Just be mindful of its current hardware and speed constraints.
For code generation that thinks like a developer—not just a tokenizer—DiffuCoder offers a compelling new direction.