Creating long, coherent, and high-quality videos from text has long been a formidable challenge in generative AI. Existing approaches—especially diffusion-based models—often sacrifice speed for quality, making real-time interaction impractical. Meanwhile, autoregressive (AR) models, while faster, struggle with visual consistency over extended durations and lack support for dynamic user input during generation.
Enter LongLive, a breakthrough frame-level autoregressive framework designed specifically for real-time, interactive long video generation. Developed by NVIDIA Labs, LongLive enables users to guide minute-long videos interactively—typing prompts on the fly—while maintaining visual fidelity, semantic coherence, and cinematic continuity. Whether you’re building an interactive storytelling app, a simulation engine, or a research prototype requiring user-in-the-loop video synthesis, LongLive offers a uniquely efficient and responsive solution.
Why LongLive Solves Real Pain Points
Traditional long video generation pipelines suffer from three critical limitations:
- Slow inference: Diffusion and diffusion-forcing models require multiple denoising steps and bidirectional attention, making them prohibitively slow for interactive use.
- Poor interactivity: Most models accept only a single static prompt, preventing dynamic narrative control during generation.
- Incoherent transitions: When new prompts are introduced mid-generation (if supported at all), visual drift or abrupt scene breaks often occur.
LongLive directly addresses these issues through a carefully engineered architecture that balances speed, quality, and controllability—without compromising on any of them.
Core Innovations Behind LongLive’s Performance
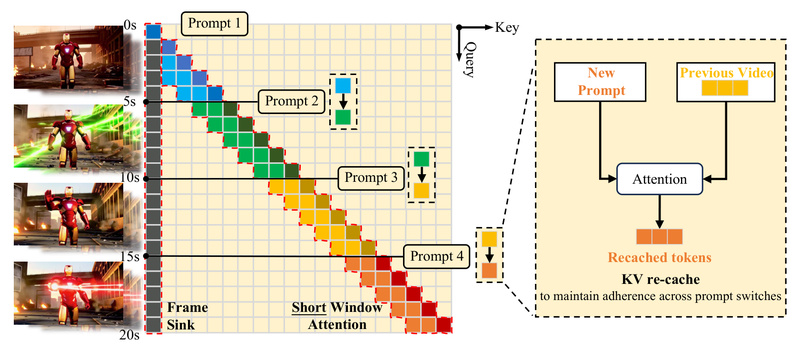
Frame-Level Autoregressive Design with Short Window Attention
LongLive adopts a causal, frame-by-frame AR approach, enabling key-value (KV) caching for fast inference. However, unlike standard AR models that degrade over long sequences, LongLive introduces two key mechanisms:
- Frame Sink: A dedicated attention token that preserves long-range visual consistency by acting as a persistent memory anchor across frames.
- Short Window Attention: Limits attention computation to a local window of recent frames, drastically reducing memory and compute overhead while retaining global coherence via the frame sink.
This combination allows LongLive to generate videos up to 240 seconds in length on a single NVIDIA H100 GPU—far beyond the capabilities of most contemporary models.
KV-Recache for Smooth Prompt Transitions
One of LongLive’s most distinctive features is its KV-recache mechanism. When a user inputs a new prompt during generation (e.g., “now the robot walks into a forest”), LongLive selectively refreshes parts of the KV cache with the new conditioning while preserving stable visual elements from prior frames. This ensures that:
- New prompts are faithfully followed
- Scene transitions remain visually smooth
- Core subjects and backgrounds stay consistent unless explicitly changed
This makes LongLive uniquely suited for interactive, user-guided storytelling—a capability rarely seen in current video generation systems.
Streaming Long Tuning: Train-Long, Test-Long Alignment
To overcome the “training-inference mismatch” common in AR video models, LongLive uses streaming long tuning. Instead of training only on short clips (e.g., 2–4 seconds), the model is fine-tuned on progressively longer sequences by reusing historical KV states and generating the next 5-second segment under teacher supervision. This ensures the model behaves consistently whether generating 10 seconds or 240 seconds—eliminating the quality drop often seen when scaling duration.
Performance That Enables Real Applications
LongLive isn’t just theoretically sound—it delivers production-ready performance:
- 20.7 FPS on a single H100 GPU (unquantized)
- 24.8 FPS with FP8 quantization and negligible quality loss
- Full INT8 support for deployment on resource-constrained systems
- Fine-tuned from a 1.3B short-clip base model in just 32 H100 GPU-days
These metrics make LongLive not only fast but also cost-efficient to adapt and deploy—critical for teams working under real-world engineering constraints.
Ideal Use Cases for Technical Teams
LongLive excels in scenarios requiring dynamic, user-influenced long-form video:
- Interactive narrative apps: Let users shape stories in real time—changing actions, settings, or styles mid-generation.
- Simulation and training environments: Generate responsive visual scenarios for robotics, autonomous systems, or virtual agents.
- Educational content tools: Create adaptive video lessons where instructors can modify explanations or visual examples on the fly.
- Creative prototyping: Rapidly iterate cinematic sequences with evolving prompts, ideal for concept art or pre-visualization.
Importantly, LongLive is optimized for cinematic “long take” styles—smooth camera motion with continuous scenes—rather than rapid cuts or montage editing. This design choice ensures coherence but also defines its best-fit applications.
Getting Started Is Straightforward
Despite its advanced capabilities, LongLive is designed for ease of adoption:
- Install dependencies in a Conda environment (requires Python 3.10, CUDA 12.4, PyTorch 2.5).
- Download model weights from Hugging Face (base model: Wan2.1-T2V-1.3B; LongLive fine-tuned weights).
- Run inference with one of two scripts:
inference.shfor single-prompt generationinteractive_inference.shfor real-time prompt streaming
The repository includes example prompts used in official demos, making it easy to reproduce results and experiment with prompt engineering strategies—such as consistently restating the subject and setting in each new prompt to maintain global coherence.
Limitations and Practical Considerations
Before integrating LongLive into your pipeline, consider the following:
- Hardware requirements: At least 40GB VRAM (H100 or A100 recommended).
- Prompt design matters: For best results, each interactive prompt should include a clear subject (“a red robot”) and setting (“in a rainy city”) to anchor continuity.
- Not ideal for rapid editing: LongLive generates seamless long takes, not shot-by-shot sequences with abrupt transitions or jump cuts.
These constraints are by design—LongLive prioritizes coherence and interactivity over stylistic flexibility in fast-paced editing scenarios.
Summary
LongLive redefines what’s possible in real-time video generation by merging efficiency, interactivity, and long-form coherence into a single, deployable framework. With support for 4-minute videos, 20+ FPS inference, and dynamic prompt control—all achievable with modest fine-tuning effort—it offers a compelling path forward for teams building the next generation of AI-powered video applications. If your project demands responsive, user-guided, long-duration video synthesis, LongLive is a solution worth serious consideration.