In today’s AI landscape, most multimodal models can describe what’s in an image—but few can reason through it. If your project involves interpreting scientific diagrams, solving visual math puzzles, or analyzing charts with logical precision, you’ve likely hit a wall with standard vision-language models. They often provide generic captions or miss subtle reasoning steps essential for accurate problem-solving.
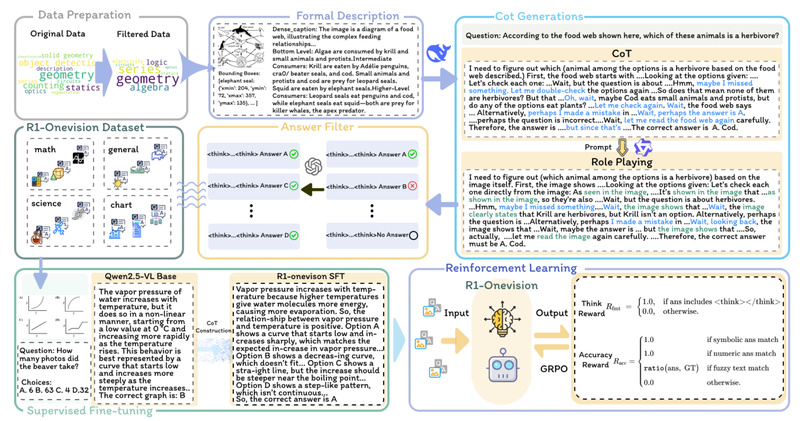
Enter R1-Onevision: a next-generation multimodal reasoning model designed not just to see but to think. Built on a novel cross-modal formalization pipeline, R1-Onevision converts visual inputs into structured textual representations, enabling deep, language-based reasoning that mirrors human analytical processes. The result? An AI assistant that doesn’t just recognize objects—it solves problems.
Developed by researchers at Zhejiang University, R1-Onevision excels in domains requiring tight integration of visual perception and logical inference—such as mathematics, physics, OCR-rich documents, and complex diagram analysis. And with its dedicated evaluation benchmark, R1-Onevision-Bench, you can objectively assess whether it meets your accuracy and reasoning depth requirements before full-scale adoption.
Why R1-Onevision Stands Out
Cross-Modal Formalization for Precise Reasoning
Unlike conventional vision-language models that treat images as loose context for text generation, R1-Onevision introduces a cross-modal reasoning pipeline. This pipeline systematically transforms visual content—whether a geometric figure, a chemistry diagram, or a multi-step math problem—into formal, text-based representations. These representations preserve structural and semantic relationships, enabling the model to apply symbolic reasoning, inference rules, and domain-specific logic—just like a human expert would.
This formalization step is the key differentiator: it shifts the model from descriptive captioning to deductive problem-solving.
State-of-the-Art Performance on Challenging Benchmarks
R1-Onevision isn’t just theoretically interesting—it delivers measurable results. According to the project’s published findings, it outperforms strong baselines like GPT-4o and Qwen2.5-VL on multiple multimodal reasoning benchmarks. This isn’t achieved through scale alone; it’s the result of targeted training strategies:
- Supervised fine-tuning on the R1-Onevision dataset—a curated collection of step-by-step multimodal reasoning examples across science, math, natural scenes, and OCR-heavy content.
- Reinforcement learning to refine answer quality, logical consistency, and generalization across unseen problem types.
The outcome is a model that doesn’t just guess—it constructs reasoned, verifiable solutions.
A Benchmark That Reflects Real-World Complexity
To address the lack of reliable evaluation tools in multimodal reasoning, the team introduced R1-Onevision-Bench—a benchmark aligned with human educational progression, from junior high school to university-level and beyond. This allows technical teams to:
- Test model performance at specific reasoning difficulty tiers.
- Compare capabilities across domains (e.g., algebra vs. biology diagrams).
- Make informed decisions about whether the model’s reasoning depth matches their use case.
This is especially valuable for educational tech, scientific AI tools, or enterprise applications where correctness matters more than fluency.
Practical Applications: Where R1-Onevision Delivers Value
R1-Onevision shines in scenarios where standard multimodal models fall short:
- Educational AI tutors that solve visual math problems with full working steps, not just final answers.
- Scientific document analysis, such as interpreting lab schematics, molecular structures, or physics diagrams.
- Intelligent document processing for forms, invoices, or technical manuals that combine text, tables, and symbols.
- AI assistants for STEM professionals who need accurate, explainable reasoning over charts, graphs, or engineering drawings.
In all these cases, the ability to generate structured, step-by-step reasoning—not just a one-sentence summary—is what makes R1-Onevision uniquely capable.
Getting Started: Integrate R1-Onevision in Minutes
For developers familiar with Hugging Face’s transformers, integrating R1-Onevision is straightforward. The model is hosted on Hugging Face Hub and built on the Qwen2.5-VL architecture, ensuring compatibility with existing vision-language workflows.
Here’s a minimal example:
from transformers import AutoProcessor, Qwen2_5_VLForConditionalGeneration
import torch
from qwen_vl_utils import process_vision_info
MODEL_ID = "Fancy-MLLM/R1-Onevision-7B"
processor = AutoProcessor.from_pretrained(MODEL_ID, trust_remote_code=True)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(MODEL_ID,trust_remote_code=True,torch_dtype=torch.bfloat16
).to("cuda").eval()
messages = [{"role": "user","content": [{"type": "image", "image": "path/to/your/image.png"},{"type": "text", "text": "Hint: Please answer the question and provide the final answer at the end. Question: Which number do you have to write in the last daisy?"},],}
]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, _ = process_vision_info(messages)
inputs = processor(text=[text], images=image_inputs, padding=True, return_tensors="pt").to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=4096)
output_text = processor.batch_decode([generated_ids[0][len(inputs.input_ids[0]):]],skip_special_tokens=True,clean_up_tokenization_spaces=False
)
print(output_text)
This code handles multimodal input preparation, model inference, and output decoding—all in under 20 lines. The model runs on GPU and supports batched inference for scalable deployment.
Limitations and Considerations
While powerful, R1-Onevision isn’t a universal solution:
- It is built on Qwen2.5-VL, so it inherits architectural constraints of that base model (e.g., fixed image resolution limits, token context window).
- It is optimized for reasoning-heavy tasks, not real-time applications or simple image classification. Inference requires GPU resources and may be slower than lightweight captioning models.
- The project is actively evolving: as of early 2025, three versions of the dataset and model have been released, indicating ongoing refinement. Users should monitor updates for improvements in robustness and domain coverage.
For teams considering adoption, we recommend testing against R1-Onevision-Bench to ensure alignment with your accuracy and latency requirements.
Summary
R1-Onevision redefines what’s possible in multimodal AI by bridging visual perception with formal reasoning. Through its cross-modal formalization pipeline, high-quality training data, and education-aligned benchmark, it offers a rare combination of depth, accuracy, and explainability. If your project demands more than surface-level image understanding—if it requires solving visual problems, not just describing them—R1-Onevision is a compelling choice worth evaluating.