If you’re building AI systems that require reliable, step-by-step mathematical reasoning—but don’t have access to proprietary datasets, massive compute budgets, or closed-source models—Light-R1 offers a compelling alternative. Developed by Qihoo360, Light-R1 is an open-source framework and model suite designed to train long Chain-of-Thought (CoT) reasoning models using only public data, open-source base models, and reproducible methods.
What makes Light-R1 stand out is not just its performance—its 14B and 32B variants surpass official DeepSeek-R1 distilled models on challenging benchmarks like AIME24 and AIME25—but also its accessibility. The entire pipeline, including training data, code, and pre-trained models, is released under the Apache 2.0 license. Even better: training a competitive model like Light-R1-32B can cost as little as (1,000 and take under 6 hours on 12×H800 GPUs.
For practitioners in education tech, technical QA, competitive programming assistance, or any domain requiring verifiable mathematical logic, Light-R1 provides a transparent, cost-effective path to deploying state-of-the-art reasoning capabilities without relying on black-box systems.
Why Light-R1 Matters for Technical Decision-Makers
Reproducible, Public-Only Training Without Compromise
Many leading reasoning models, including those in the DeepSeek-R1 series, rely on internal, non-public datasets that make independent replication impossible. Light-R1 flips this paradigm by demonstrating that comparable—or even superior—performance can be achieved using exclusively public data sources such as OpenR1-Math-220k, Omni-MATH, and AIME (pre-2024).
Critically, the team performed rigorous decontamination using both exact matching (excluding digits) and 32-gram overlap checks to ensure zero leakage from evaluation benchmarks like AIME24/25 and MATH-500. This means reported results are trustworthy and comparable—essential for fair model selection in research or production.
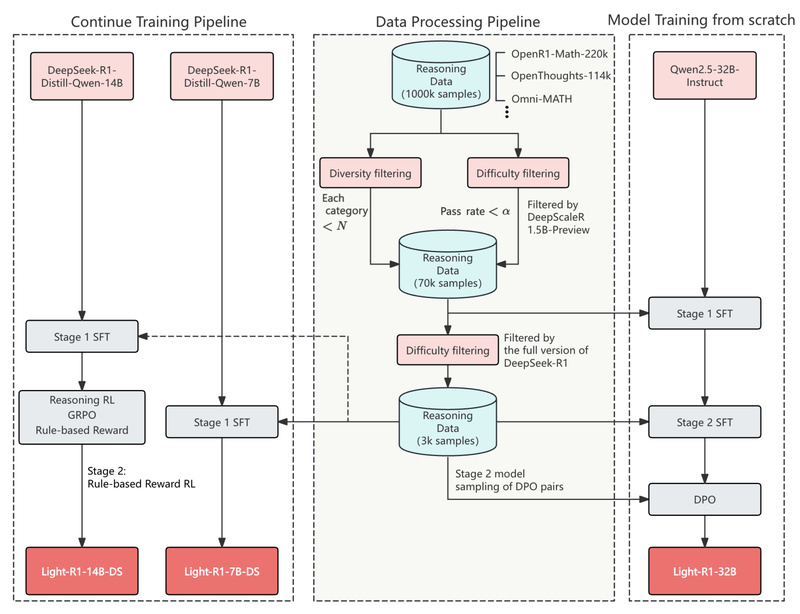
Curriculum Learning: Structured Progression from Simple to Hard
Light-R1’s training pipeline follows a curriculum strategy across three stages:
- SFT Stage 1: A broad 76k dataset of verified responses generated by DeepSeek-R1, filtered by difficulty using a smaller verifier model.
- SFT Stage 2: A focused 3k high-difficulty subset that significantly boosts performance—even when applied to already-distilled models like DeepSeek-R1-Distill-Qwen-32B.
- DPO (Direct Preference Optimization): Preference pairs are constructed from correct vs. incorrect model generations, then used to align the model with desired reasoning behavior.
This staged approach ensures steady, measurable improvements at each step—visible in the progression from 69.0 → 73.0 → 75.8 → 76.6 on AIME24 for the 32B model.
Reinforcement Learning Works—But Isn’t Required
While Light-R1’s core innovation lies in its efficient SFT+DPO pipeline, the team also successfully applied GRPO (a variant of RLHF) to produce Light-R1-14B-DS—the current SOTA 14B model on AIME24 (74.0) and AIME25 (60.2). Notably, this 14B model outperforms many 32B competitors and even DeepSeek-R1-Distill-Llama-70B.
However, the project emphasizes that RL is optional: the SFT+DPO path alone delivers strong results with far greater stability, lower cost, and easier debugging—making it ideal for real-world deployment.
Key Technical Advantages
Full Openness: Models, Data, and Code
Unlike many “open-weight” releases that omit training details, Light-R1 provides:
- Pre-trained models (7B, 14B, 32B) on Hugging Face
- All curriculum SFT and DPO datasets
- Training scripts built on 360-LLaMA-Factory
- Evaluation suite based on DeepScaleR, including full logs and 64-run averaging protocols
This end-to-end transparency enables full reproducibility—critical for academic validation and enterprise adoption.
Extremely Low Training Cost
The entire SFT+DPO pipeline for Light-R1-32B is estimated to run in under 6 hours on 12×H800 GPUs, costing ~)1,000. This democratizes access to high-performance reasoning models for labs and startups without cloud-scale budgets.
Specialized Yet Generalizable
Though trained primarily on math, Light-R1 models show surprising cross-domain strength. For instance, Light-R1-32B scores 61.8 on GPQA Diamond—a scientific reasoning benchmark it was never trained on—demonstrating that focused training doesn’t necessarily hurt broad capability. That said, minor forgetting on non-math scientific tasks is observed, so domain alignment remains important.
Practical Usage Guide
Inference: Don’t Forget the <think> Token
Light-R1 inherits Qwen’s chat template but adds special tokens <think> and </think>. To activate reasoning, you must hard-code <think> right before the model’s response position in the prompt—exactly as done in DeepSeek-R1.
Recommended inference engines: vLLM or SGLang, both of which support custom token handling and high-throughput generation.
Training Your Own Variant
Want to adapt Light-R1 to your domain? Follow these steps:
- Clone the GitHub repo
- Use the provided curriculum datasets in
data/ - Run training with the 360-LLaMA-Factory scripts in
train-scripts/ - Evaluate using the DeepScaleR-based eval suite with 64-run averaging for stable metrics
Even fine-tuning an existing distilled model (e.g., DeepSeek-R1-Distill-Qwen-14B) with Light-R1’s 3k-stage2 data yields SOTA results—making it a powerful drop-in enhancement.
Limitations to Consider
- Math-specialized: While general reasoning is possible, peak performance is in mathematical problem-solving. Don’t expect optimal results on legal, medical, or creative tasks.
- Requires explicit reasoning trigger: Without
<think>in the prompt template, the model may skip CoT and give direct (often incorrect) answers. - Not general-purpose: Light-R1 is a reasoning specialist, not a chat assistant. Use it where verifiable, step-by-step logic matters most.
- RL is advanced: While demonstrated, GRPO training requires more expertise and tuning than the default SFT+DPO flow.
Summary
Light-R1 proves that world-class mathematical reasoning models can be built transparently, affordably, and entirely from public resources. By combining curriculum learning, rigorous decontamination, and efficient post-training (SFT → DPO → optional RL), it delivers SOTA performance across 7B, 14B, and 32B scales—often beating models trained with proprietary data.
For technical leaders evaluating reasoning infrastructure, Light-R1 offers a rare combination: reproducibility, cost efficiency, and benchmark-leading results. Whether you’re deploying a math tutoring bot, enhancing a technical documentation assistant, or researching long-CoT architectures, Light-R1 provides a validated, open foundation to build upon—without hidden dependencies or unverifiable claims.