Building reliable computer use agents (CUAs)—systems that can autonomously interact with graphical user interfaces (GUIs)—has long been hindered by a critical bottleneck: the scarcity of large-scale, high-quality, open training data. Unlike image-text pairs abundant on the web, real-world GUI interaction trajectories are expensive to collect, platform-specific, and rarely shared. This limits both the performance and generalization of existing vision-language models (VLMs) in practical automation scenarios.
Enter ScaleCUA: an open-source, cross-platform computer use agent that directly tackles this data gap. Developed by OpenGVLab, ScaleCUA introduces a massive dataset spanning six operating systems (Ubuntu, Android, Web, macOS, Windows, and more) and three core task domains, curated through a closed-loop pipeline that combines automated exploration with human expert validation. Trained on this rich, diverse data, ScaleCUA delivers state-of-the-art performance across desktop, mobile, and web environments—without requiring platform-specific fine-tuning. For engineers, researchers, and product teams looking to automate GUI tasks reliably at scale, ScaleCUA offers a unified, open, and reproducible foundation.
Why ScaleCUA Solves a Real Pain Point
Traditional approaches to GUI automation often rely on brittle scripting (e.g., Selenium for web, ADB for Android) or accessibility APIs that vary wildly across platforms. Modern VLM-based agents promise more robust, perception-driven interaction—but they fail in practice when trained on narrow or synthetic datasets.
ScaleCUA addresses this by recognizing a simple truth: general-purpose GUI agents need general-purpose data. By collecting real interaction traces across diverse OS environments and task types—from file management on Ubuntu to app navigation on Android and form filling on the web—ScaleCUA enables a single model to understand and act in varied visual contexts. This eliminates the need to build and maintain separate agents for each platform, significantly reducing engineering overhead and accelerating deployment.
Cross-Platform Out of the Box
One of ScaleCUA’s defining strengths is its native cross-platform capability. The agent is not merely evaluated on multiple systems—it is trained on them jointly. This means:
- No retraining or adapter layers are needed when switching from Windows to macOS or Android.
- The same inference pipeline works across environments, as long as the agent receives a screenshot and a natural language instruction.
- Teams managing heterogeneous device fleets (e.g., enterprise IT, QA labs, accessibility tools) can deploy one agent instead of five.
This universality stems directly from the design of the ScaleCUA-Data dataset, which deliberately captures visual and operational diversity—ensuring the model learns platform-agnostic concepts like “click the blue button” or “drag this file to the folder” rather than memorizing UI quirks of a single OS.
Performance That Matters in Practice
ScaleCUA isn’t just theoretically broad—it’s empirically strong. On widely adopted benchmarks, it sets new records:
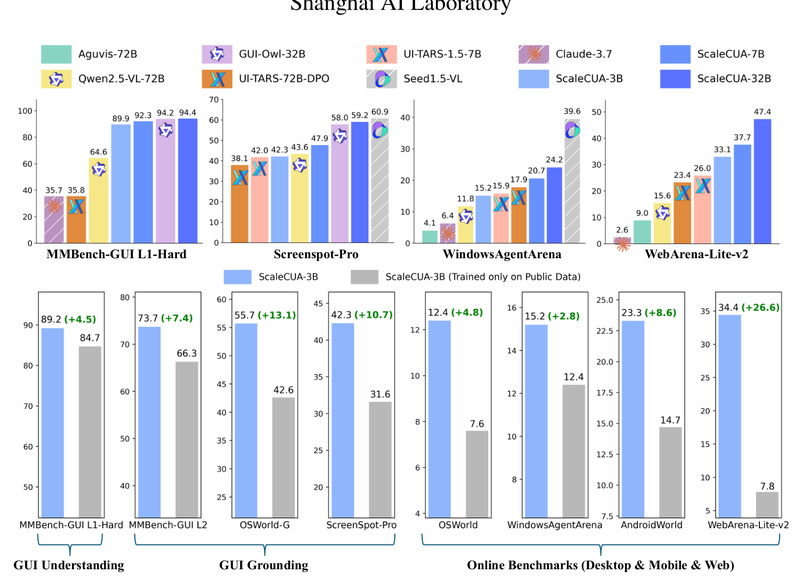
- 94.4% on MMBench-GUI L1-Hard (a challenging visual GUI reasoning test)
- 60.6% success rate on OSWorld-G (Ubuntu desktop automation)
- 47.4% on WebArena-Lite-v2 (web-based task completion)
- +26.6 absolute improvement over prior baselines on WebArena-Lite-v2
These aren’t academic curiosities. They reflect real-world reliability: Can the agent correctly locate a UI element? Execute a multi-step workflow? Recover from minor visual variations? The numbers suggest ScaleCUA handles these with unprecedented consistency—especially for an open-source solution.
Get Started Quickly with Playground and APIs
You don’t need to train from scratch to test ScaleCUA. The project provides:
- An interactive Playground with pre-configured virtual environments for Ubuntu, Android, and Web. Just deploy the model and start giving natural language commands.
- vLLM-based deployment with an OpenAI-compatible API, enabling seamless integration into existing LLM pipelines or automation frameworks.
- Support for two operational modes:
- Native Agentic Model: A single model handles both planning and UI grounding.
- Agentic Workflow: Separate models for high-level planning and low-level UI action prediction (useful for modular tuning).
This lowers the barrier to experimentation—whether you’re a researcher validating agent robustness or a developer prototyping an internal automation tool.
Full Transparency: Open Data, Models, and Training Code
ScaleCUA follows a truly open ethos:
- ScaleCUA-Data is publicly available on HuggingFace—a rare large-scale dataset of real GUI interaction trajectories across platforms.
- Pre-trained models based on Qwen2.5-VL and InternVL are released, allowing immediate use or fine-tuning.
- The agent-sft training framework includes configs, scripts, and documentation to reproduce results or adapt the agent to custom domains.
This stack empowers users to inspect, modify, and extend the system without vendor lock-in—critical for academic reproducibility and enterprise customization.
Practical Limitations to Keep in Mind
While powerful, ScaleCUA has constraints worth considering:
- Vision-only input: The agent operates solely on screenshots. It cannot access DOM trees, accessibility metadata, or internal application states. This limits precision in highly dynamic or text-sparse interfaces.
- GPU resource requirements: Like most modern VLMs, real-time inference demands capable GPUs—making edge deployment challenging without optimization.
- Dependency on vLLM: The recommended deployment path relies on vLLM, which may require infrastructure adjustments in some environments.
These limitations don’t negate ScaleCUA’s value but help set realistic expectations for integration.
When Should You Adopt ScaleCUA?
ScaleCUA shines in scenarios where:
- You need cross-platform GUI automation without maintaining separate toolchains.
- Tasks are visually grounded and can be described in natural language (e.g., “Upload this file to the shared drive” or “Book a meeting for tomorrow at 2 PM”).
- You want an open, inspectable foundation for research or product development—avoiding black-box commercial APIs.
Ideal use cases include cross-platform QA testing, assistive technologies for users with motor impairments, internal workflow automation (e.g., HR or finance portals), and foundational research in general-purpose embodied agents.
Summary
ScaleCUA represents a significant leap in open-source computer use agents—not through architectural novelty alone, but through disciplined scaling of high-quality, cross-platform data. By solving the data bottleneck head-on, it delivers a single agent that works reliably across Ubuntu, Android, Web, macOS, and Windows, backed by strong benchmarks, easy-to-use tooling, and full openness. For practitioners tired of fragmented, platform-locked automation solutions, ScaleCUA offers a unified, transparent, and performant alternative ready for real-world adoption.