Deploying large language models (LLMs) in real-world applications remains a major engineering challenge. While models like LLaMA-2, Falcon, and Mixtral deliver impressive performance, their massive memory footprints—often exceeding 70GB—make them impractical for most edge devices, single-GPU servers, or cost-sensitive cloud environments.
Post-training quantization (PTQ) offers a promising path to shrink these models without full retraining, but traditional PTQ methods often fail catastrophically at ultra-low bit widths (e.g., 2–4 bits), especially when quantizing both weights and activations. This is where OmniQuant steps in: a simple, efficient, and highly accurate quantization framework that enables near-lossless compression of LLMs—even down to 2-bit weights—while running entirely on a single A100 GPU with just 128 calibration samples.
Unlike complex quantization-aware training (QAT) pipelines, OmniQuant operates as a drop-in PTQ solution that delivers state-of-the-art results across diverse configurations (W4A4, W3A16, W2A16, etc.) and integrates seamlessly with real-world deployment stacks like MLC-LLM for immediate speedups on mobile phones and consumer GPUs.
Why Quantization Matters—and Why Most PTQ Methods Fall Short
LLMs are compute- and memory-intensive. A 70B-parameter model like LLaMA-2-70B requires over 140GB of GPU memory in FP16—far beyond the capacity of most data centers, let alone mobile devices. Quantization reduces model size and computational load by representing weights and activations with fewer bits (e.g., 4-bit integers instead of 16-bit floats).
However, naïve quantization destroys model accuracy due to two persistent issues:
- Weight outliers: A few extreme weight values distort the quantization range, causing significant information loss.
- Activation outliers: Certain channels in activations exhibit abnormally high values, making uniform quantization ineffective.
Existing PTQ methods often address these problems with hand-crafted heuristics—like fixed clipping thresholds or static scaling—which work poorly under extreme compression. The result? Models that either run fast but produce gibberish or retain accuracy only at relatively high bit widths (e.g., W8A8), negating most memory savings.
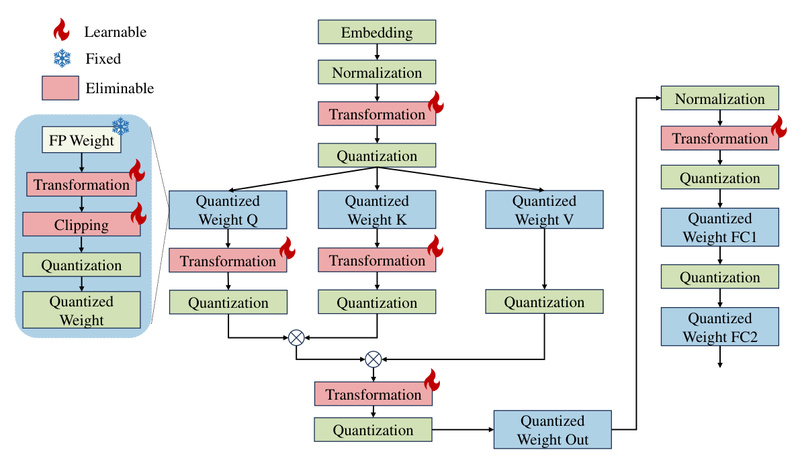
OmniQuant solves this by replacing heuristics with learnable, differentiable calibration—enabling the model to adapt its own quantization behavior during a lightweight optimization phase.
OmniQuant’s Core Innovations: Simplicity Meets Accuracy
OmniQuant introduces two key components that jointly optimize the quantization process without requiring task-specific fine-tuning or massive calibration datasets:
Learnable Weight Clipping (LWC)
Instead of using a fixed clipping threshold to suppress weight outliers, OmniQuant treats the clipping bound as a learnable parameter. During a short calibration phase (typically 20 epochs on 128 samples), it optimizes this threshold to minimize reconstruction error—preserving model fidelity even at 2- or 3-bit precision.
Learnable Equivalent Transformation (LET)
Activation outliers are particularly damaging in low-bit activation quantization (e.g., W4A4). Rather than quantizing activations directly, LET applies a linear transformation that shifts the quantization burden from activations to weights—a mathematically equivalent operation that is far easier to quantize accurately. This transformation is also learned during calibration, ensuring optimal adaptation to each layer’s statistical profile.
Together, LWC and LET operate within a block-wise error minimization framework, making OmniQuant both highly effective and computationally efficient. Users can quantize a 70B model in under 16 hours on a single A100-40G GPU.
Supported Quantization Modes and Model Coverage
OmniQuant supports two major quantization paradigms:
- Weight-only quantization: Ideal for scenarios where activations remain in higher precision (e.g., W3A16, W2A16). This mode maximizes compatibility with existing inference engines while drastically cutting memory usage—for example, reducing Mixtral-8x7B’s footprint from 87GB to 23GB with near-lossless quality.
- Weight-activation quantization: For maximum speedup, OmniQuant also supports symmetric low-bit quantization of both weights and activations (e.g., W6A6, W4A4), enabled via the
--letflag.
The framework provides pre-quantized checkpoints for a wide range of models, including:
- LLaMA-1 & LLaMA-2 (7B to 70B)
- LLaMA-2-Chat
- OPT (125M to 66B)
- Falcon (including Falcon-180B, compressible to 65GB for single-GPU inference)
- Mixtral-8x7B
This ready-to-use “Model Zoo” lets practitioners skip calibration entirely and deploy quantized models immediately.
Real-World Deployment Made Easy with MLC-LLM
Quantization only delivers value if it translates to real hardware improvements. OmniQuant integrates with MLC-LLM, a universal deployment engine that compiles quantized models for diverse backends—including NVIDIA, AMD, and Intel GPUs, as well as iOS and Android devices.
For example, OmniQuant’s W3A16g128 quantization of LLaMA-2-7B-Chat runs on smartphones with as little as 4.5GB of free RAM, enabling on-device AI without cloud dependency. Benchmarks show tangible reductions in memory usage and measurable inference speedups—unlike some PTQ methods that save memory but slow down execution due to inefficient kernels.
Getting Started: A Minimal, Reproducible Workflow
OmniQuant is designed for usability. Here’s how to quantize LLaMA-7B to W3A16 in minutes:
-
Install dependencies:
conda create -n omniquant python=3.10 -y conda activate omniquant git clone https://github.com/OpenGVLab/OmniQuant.git cd OmniQuant && pip install -e . # Install the patched AutoGPTQ kernel for real quantization git clone https://github.com/ChenMnZ/AutoGPTQ-bugfix && pip install -v .
-
Optionally download precomputed activation statistics (or generate your own):
git clone https://huggingface.co/ChenMnZ/act_scales git clone https://huggingface.co/ChenMnZ/act_shifts
-
Run quantization:
CUDA_VISIBLE_DEVICES=0 python main.py --model /path/to/llama-7b --wbits 3 --abits 16 --lwc --epochs 20 --output_dir ./log/llama-7b-w3a16 --eval_ppl
-
Evaluate or deploy: Use
--resumeto load pre-trained OmniQuant parameters for zero-epoch evaluation, or--save_dirto export the quantized model for MLC-LLM compilation.
The entire process requires no labeled data, no task-specific tuning, and minimal GPU resources—making it ideal for rapid prototyping and production deployment alike.
Limitations and Practical Considerations
While OmniQuant sets a new standard for PTQ accuracy, users should keep the following in mind:
- Inference speed in weight-only mode: Real quantization (via AutoGPTQ kernels) reduces memory usage but may not accelerate inference for weight-only schemes due to kernel inefficiencies. Speedups are more consistent in weight-activation quantization or when using MLC-LLM.
- Accuracy vs. compression trade-offs: 2-bit quantization achieves extreme compression but incurs noticeable quality drops—best suited for experimental or highly constrained mobile scenarios. For most applications, W3A16 or W4A16 offers the best balance.
- Calibration data requirement: OmniQuant needs a small unlabeled dataset (128 samples by default) for calibration. This is standard for PTQ but requires access to representative input data.
- Model support: Always check the OmniQuant Model Zoo for your target architecture. While coverage is broad, not all community models are guaranteed to work out of the box.
How OmniQuant Compares to SmoothQuant, AWQ, and GPTQ
Unlike SmoothQuant, which relies on fixed activation smoothing, or AWQ, which preserves only a subset of “sensitive” weights, OmniQuant uses joint, differentiable optimization of both weights and activations. This leads to better accuracy across bit widths—especially in symmetric low-bit settings like W4A4, where most competitors struggle.
Compared to GPTQ, OmniQuant avoids iterative weight updates and instead focuses on calibrating quantization parameters, making it faster and more stable. It also uniquely supports both weight-only and weight-activation quantization within the same framework—offering flexibility that most tools lack.
Summary
OmniQuant bridges the gap between theoretical quantization research and real-world LLM deployment. By combining learnable calibration with a lightweight, sample-efficient workflow, it enables engineers and researchers to compress state-of-the-art models to 2–4 bits with minimal accuracy loss—and deploy them on everything from cloud GPUs to smartphones. Whether you’re cutting cloud costs, enabling on-device AI, or pushing the limits of model compression, OmniQuant offers a practical, powerful, and production-ready solution.