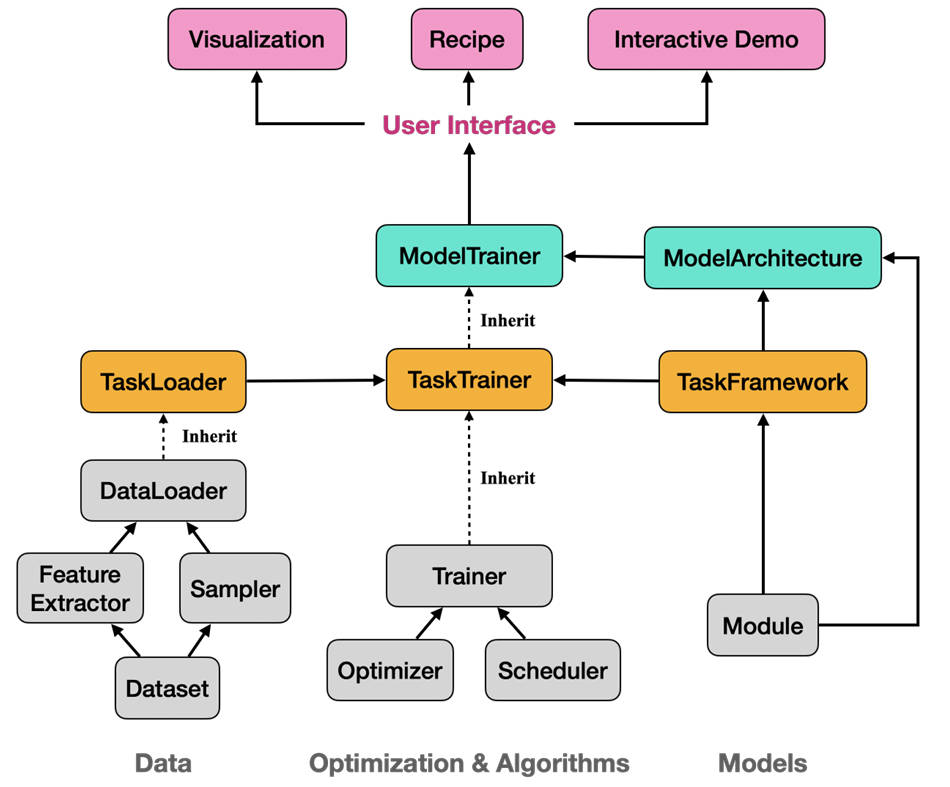
Amphion is an open-source toolkit purpose-built for audio, music, and speech generation that dramatically lowers the entry barrier for junior researchers, engineers, and developers. Rather than requiring deep expertise in signal processing or years of trial-and-error with fragmented tools, Amphion offers a cohesive, beginner-friendly framework that unifies state-of-the-art models, pre-trained checkpoints, standardized evaluation metrics, and intuitive visualizations—all under a single, well-documented codebase.
At its core, Amphion addresses a critical pain point in audio AI: the fragmentation of tools, datasets, and evaluation practices across tasks like Text-to-Speech (TTS), Voice Conversion (VC), and Singing Voice Conversion (SVC). By integrating these disparate elements into a consistent workflow, Amphion enables users to prototype, reproduce, and deploy high-quality audio generation systems—often in just hours.
Solves Real Problems with Supported Generation Tasks
Amphion ships with robust support for several key audio generation tasks, each solving tangible challenges in real-world applications:
- Text-to-Speech (TTS): From classic architectures like FastSpeech2 and VITS to cutting-edge zero-shot models like MaskGCT and Vevo-TTS, Amphion enables natural, multilingual speech synthesis without speaker-specific fine-tuning. MaskGCT, for instance, eliminates the need for explicit text-speech alignment—a major bottleneck in traditional TTS pipelines.
- Voice Conversion (VC): Amphion supports zero-shot voice cloning with models like Vevo and FACodec. These can transfer a target speaker’s voice from just a few seconds of reference audio while preserving linguistic content or even controlling timbre and prosody separately.
- Singing Voice Conversion (SVC): Convert any source singing voice to match a target singer’s vocal characteristics. Amphion leverages diffusion-based models and supports multiple content encoders (e.g., Whisper, ContentVec) to ensure high fidelity and expressiveness.
- Accent Conversion (AC): Modify a speaker’s accent without altering identity or linguistic content—useful for language learning tools or localized voice assistants—using Vevo-Style in a zero-shot manner.
- Text-to-Audio (TTA): Generate arbitrary environmental sounds or music-like audio from text prompts, implemented via latent diffusion models similar to AudioLDM.
These capabilities are not academic demos—they’re backed by models that achieve state-of-the-art (SOTA) performance on public benchmarks and are trained on large-scale, real-world datasets like Emilia.
Integrated Components That Eliminate Common Bottlenecks
Amphion goes beyond just model implementations—it solves the “glue problem” that plagues audio AI development:
- Pre-trained models: Users can skip weeks of training and immediately run inference with SOTA checkpoints for TTS, VC, SVC, and more.
- Neural vocoders: Amphion bundles a comprehensive suite of vocoders—including HiFi-GAN, BigVGAN, WaveGlow, and DiffWave—ensuring high-fidelity waveform synthesis out of the box. It also introduces novel discriminators like the Multi-Scale Constant-Q Transform Discriminator to boost GAN-based vocoder quality without affecting inference speed.
- Standardized evaluation: Instead of reinventing metrics, Amphion provides ready-to-use tools for assessing F0 accuracy, energy modeling, intelligibility (via Whisper-based WER/CER), speaker similarity (using WavLM or RawNet3), and audio quality (via FAD, PESQ, STOI, and MCD).
- Unified data preprocessing: Amphion normalizes data preparation across 10+ public datasets (LibriTTS, VCTK, M4Singer, etc.) and uniquely supports Emilia—a 200,000+ hour in-the-wild multilingual speech dataset—and its preprocessing pipeline Emilia-Pipe, which automatically cleans noisy audio and extracts linguistic and speaker annotations.
Beginner-Friendly Design with Interactive Visualizations
Understanding how complex generative models work is notoriously difficult. Amphion tackles this with SingVisio, its first interactive visualization tool that reveals the inner workings of diffusion models during singing voice conversion. This transparency helps newcomers debug, learn, and build intuition—without needing to read 50 pages of academic papers.
This educational focus aligns with Amphion’s north-star goal: to serve as a platform for studying how any input (text, reference audio, style tokens) can be converted into high-quality audio.
Get Started in Minutes
Amphion prioritizes quick onboarding:
- Installation via conda:
git clone https://github.com/open-mmlab/Amphion.git cd Amphion conda create --name amphion python=3.9.15 conda activate amphion sh env.sh
- Or via Docker:
Pre-built images with GPU support allow one-command startup, ideal for reproducible experiments across machines. - Task-specific recipes: Every supported task (TTS, VC, SVC, etc.) comes with ready-to-run scripts for training, inference, and evaluation—so users can go from “zero to audio” in under an hour.
Current Limitations and Roadmap
While Amphion v0.2 is production-ready for several tasks, some capabilities are still maturing. Notably, Singing Voice Synthesis (SVS) and Text-to-Music (TTM) are marked as “developing,” meaning core infrastructure exists but full model support or pre-trained weights may not yet be public. Users should consult the GitHub repository for the latest status.
That said, Amphion’s modular design makes it easy to extend—new models or datasets can be integrated with minimal boilerplate.
Why Choose Amphion Over Other Toolkits?
Amphion stands out for four reasons:
- Unified framework: One codebase for TTS, VC, SVC, AC, and TTA—no need to juggle separate repositories.
- Zero-shot emphasis: Leading models like MaskGCT (TTS) and Vevo (VC/SVC) enable speaker adaptation without fine-tuning.
- Large-scale open data: Exclusive support for the Emilia dataset empowers research on in-the-wild, multilingual speech.
- Active innovation: With multiple papers accepted at ICLR 2025, IEEE SLT 2024, and NeurIPS 2023, Amphion is not just a library—it’s a living research platform.
For teams building voice assistants, dubbing tools, karaoke apps, or generative audio products, Amphion offers a future-proof foundation that balances accessibility with cutting-edge performance.
Summary
Amphion is more than a toolkit—it’s a gateway into modern audio generation. By unifying SOTA models, evaluation standards, and educational visualizations in a beginner-friendly package, it empowers developers and researchers to focus on innovation rather than infrastructure. Whether you’re prototyping a voice clone app or benchmarking a new vocoder, Amphion provides the tools, data, and clarity to move fast—without sacrificing scientific rigor.