Creating lifelike talking head videos—where a static portrait speaks and moves in sync with an audio or driving video—has long been a challenging problem in computer vision and generative AI. Most existing methods rely solely on 2D facial appearance and motion cues, often resulting in artifacts, unnatural head movements, or background distortions.
DaGAN++ (Depth-Aware Generative Adversarial Network++) addresses these limitations by introducing a practical, self-supervised approach to leverage dense 3D facial geometry—specifically pixel-wise depth—without requiring expensive 3D annotations, calibrated cameras, or explicit 3D models during training. Developed by researchers from the Hong Kong University of Science and Technology and Alibaba Cloud, DaGAN++ delivers state-of-the-art realism on major benchmarks like VoxCeleb1, VoxCeleb2, and HDTF, making it a compelling choice for practitioners seeking high-quality, controllable face reenactment.
Why Depth Matters in Talking Head Generation
Traditional 2D-only models struggle when head pose changes significantly or when complex backgrounds interfere with motion estimation. Without understanding the underlying 3D structure of the face, these models often warp textures unnaturally or fail to preserve identity during extreme rotations.
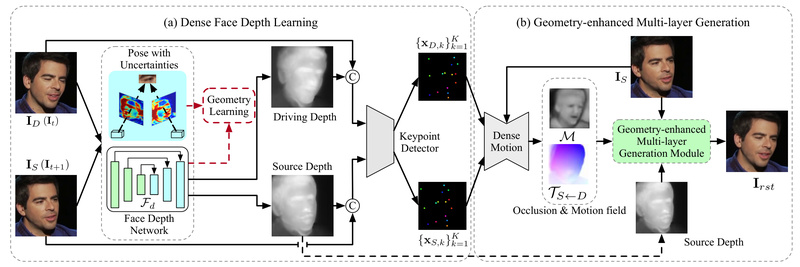
DaGAN++ solves this by estimating per-pixel depth directly from monocular face videos in a self-supervised manner. This depth map isn’t just auxiliary—it actively guides every stage of the generation pipeline, from motion modeling to image synthesis. The result? Sharper, more anatomically plausible facial movements and significantly reduced background leakage or flickering.
Core Technical Innovations
Self-Supervised Facial Depth Learning
DaGAN++ introduces a novel method to learn dense facial depth from casually captured videos—no 3D scans, no motion capture, no camera intrinsics. It even models pixel-level uncertainty to identify reliable rigid-motion regions (like the nose or forehead), improving depth estimation robustness under expression changes.
Geometry-Guided Keypoint Estimation
Instead of relying on generic facial landmarks, DaGAN++ uses the estimated depth to refine keypoint detection. This geometry-aware module produces more stable and spatially accurate motion fields, which directly translate to smoother and more natural head motion in the output video.
Cross-Modal Appearance-Depth Attention
At the heart of DaGAN++’s generator is a 3D-aware attention mechanism that fuses appearance (RGB) and depth information at multiple scales. This coarse-to-fine integration ensures that structural details—like jawline contours or cheekbone depth—are preserved consistently across frames, even during rapid motion.
Practical Use Cases
DaGAN++ is particularly valuable in applications where visual fidelity and identity preservation are critical:
- Virtual avatars: Generate personalized, expressive digital humans from a single photo.
- Video dubbing: Reenact a speaker’s lip and head motion to match translated audio.
- Content creation: Produce talking-head marketing or educational videos without reshooting.
- Accessibility tools: Animate static portraits for assistive communication.
All it requires is one source image and a driving video (e.g., from a different person speaking), making it highly versatile for real-world deployment.
Getting Started with DaGAN++
The project is open-source and designed for accessibility:
-
Clone the repository:
git clone https https://github.com/harlanhong/CVPR2022-DaGAN.git
-
Install dependencies, including the embedded
face-alignmentlibrary. -
Run inference with pre-trained models using a single command:
python demo.py --config config/vox-adv-256.yaml --source_image source.png --driving_video drive.mp4 --checkpoint path/to/model.pth --relative --adapt_scale --kp_num 15 --generator DepthAwareGenerator
-
Prepare inputs: Both source and driving videos must be face-cropped. The repo includes a helper script (
crop-video.py) to automate this using ffmpeg suggestions.
For quick experimentation, a Gradio-based demo is also available on Hugging Face Spaces (CPU version live; GPU version upcoming).
Training and Customization
Training DaGAN++ from scratch is resource-intensive—it’s optimized for multi-GPU setups (e.g., 8×RTX 3090) and large-scale datasets like VoxCeleb. However, the team provides both depth estimation models and full DaGAN++ checkpoints, enabling most users to skip training entirely.
For custom datasets:
- Organize videos as folders of PNG frames (recommended for I/O efficiency).
- Create a YAML config pointing to your data root.
- Adjust batch size and epochs based on your hardware.
Note: The newer MCNet (ICCV 2023) from the same authors eliminates the need for a separate depth network, offering a lighter alternative if depth estimation becomes a bottleneck.
Limitations to Consider
While powerful, DaGAN++ has practical boundaries:
- Input constraints: Faces must be tightly cropped; profile views or occlusions degrade quality.
- Identity consistency: Works best when source and driver share similar facial structure. Extreme pose mismatches (e.g., frontal source + profile driver) may cause artifacts.
- Non-human faces: Not designed for cartoons, animals, or stylized characters without fine-tuning—though the included “cartoon.mp4” demo shows some transferability.
- Compute requirements: Full training demands high-end GPUs, though inference runs on a single GPU.
Summary
DaGAN++ sets a new standard for talking head video generation by seamlessly integrating self-supervised 3D depth into a generative pipeline. It solves real-world problems—background noise, unnatural motion, identity drift—without the impractical burden of 3D annotations. With public code, pre-trained models, and clear documentation, it’s a production-ready solution for researchers and engineers building next-generation face animation systems. For teams prioritizing realism and geometric coherence, DaGAN++ offers a robust, depth-aware foundation that’s both innovative and accessible.