Audio-driven facial animation has long been a challenging yet highly valuable capability—from building expressive virtual agents to creating personalized pet videos from voice messages. Traditional methods often struggle with video length, inter-frame flickering, or require extensive per-character training. Enter JoyVASA, an open-source, diffusion-based framework that cleanly separates static facial appearance from dynamic motion, enabling high-quality, lip-synced animations for both humans and animals using nothing more than a single reference image and an audio clip.
What sets JoyVASA apart is its decoupled design: motion is generated independently of identity, allowing any static portrait or animal image to be animated with realistic facial expressions and head movements derived directly from speech. Trained on a hybrid dataset of English and Chinese speech, it supports multilingual inputs out of the box—making it a practical choice for global applications without rebuilding the model from scratch.
For developers, researchers, and product teams seeking a flexible, reusable, and expressive animation pipeline that avoids the inefficiencies of end-to-end video diffusion models, JoyVASA offers a compelling balance of quality, generalization, and ease of use.
Key Innovations That Address Real Pain Points
Decoupled Facial Representation for Flexible Reuse
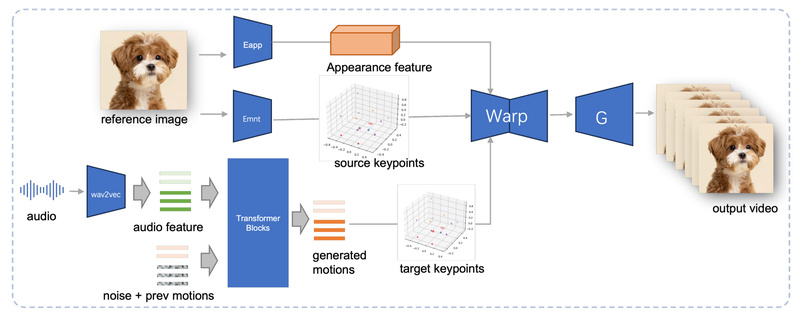
Traditional audio-to-video models tightly couple appearance and motion, meaning each new character often requires retraining or fine-tuning. JoyVASA breaks this dependency by splitting the problem into two stages:
- Static 3D facial representation: Extracted once from a reference image (using components from LivePortrait).
- Dynamic motion sequence: Generated purely from audio, agnostic to who—or what—is speaking.
This separation means you can animate any human or animal photo with motion sequences trained on entirely different subjects. Need to create 100 avatars from 100 profile pictures? No retraining needed—just swap the reference image.
Identity-Independent Motion Generation via Diffusion Transformer
JoyVASA trains a diffusion transformer to map audio features (from wav2vec2 or Chinese HuBERT) directly to motion trajectories—specifically 3D facial keypoints representing expression and head pose. Because this motion generator doesn’t “see” the face it’s animating, it generalizes across identities, species, and even art styles, as long as the underlying motion space is compatible.
This approach eliminates the need for character-specific datasets and dramatically reduces inference complexity compared to full-video generative models.
Unified Framework for Humans and Animals
Most talking-head systems are built exclusively for humans. JoyVASA extends its architecture to animals by leveraging specialized modules (like X-Pose) trained on animal facial dynamics. With a simple flag (--animation_mode animal), the same pipeline animates your cat, dog, or cartoon creature with plausible lip and head motion synced to your voice.
This cross-species capability opens doors for pet tech, animated storytelling, and emotionally expressive non-human characters in games or companionship apps.
Multilingual Audio Support
Trained on both public English data and private Chinese speech corpora, JoyVASA supports bilingual inputs without modification. At launch, the Chinese HuBERT encoder is fully integrated, with wav2vec2 (for English and other languages) support coming soon. This makes JoyVASA immediately useful in multilingual markets without requiring custom audio preprocessing pipelines.
Practical Use Cases for Teams and Builders
- Virtual Assistants & Customer Service Avatars: Generate lifelike, lip-synced agents that speak in the user’s language, using your brand’s visual identity—no per-agent training required.
- Personalized Pet Videos: Let users upload a photo of their dog and a voice message to create a “talking pet” clip for social sharing or emotional connection.
- Educational & Marketing Content: Rapidly produce talking-head videos in multiple languages for courses, ads, or social media using stock photos or illustrated characters.
- Game & Entertainment Prototyping: Animate NPC faces or animal companions during pre-production using placeholder art and voice lines, accelerating iteration.
Because JoyVASA doesn’t require per-character motion capture or fine-tuning, it lowers the barrier to dynamic character animation significantly.
Getting Started: Simple Setup, Immediate Results
JoyVASA is designed for usability, even for those without deep ML expertise. Here’s how to run it in minutes:
-
Set up the environment:
conda create -n joyvasa python=3.10 -y conda activate joyvasa pip install -r requirements.txt
-
Download pretrained weights into
pretrained_weights/, including:- JoyVASA motion generator
- LivePortrait models (for human and animal)
- Chinese HuBERT or wav2vec2 audio encoder
-
Run inference with a single command:
For humans:python inference.py -r assets/examples/imgs/joyvasa_003.png -a assets/examples/audios/joyvasa_003.wav --animation_mode human --cfg_scale 2.0
For animals:
python inference.py -r assets/examples/imgs/joyvasa_001.png -a assets/examples/audios/joyvasa_001.wav --animation_mode animal --cfg_scale 2.0
-
Adjust expressiveness with
--cfg_scale: higher values yield more exaggerated expressions and head movements.
A Gradio-based web demo (python app.py) is also included for interactive testing at http://127.0.0.1:7862.
Important Limitations to Consider
While JoyVASA offers strong capabilities, it’s essential to understand its current boundaries:
- Not real-time: Inference is offline and may take several seconds per second of video, depending on hardware.
- GPU required: Tested on NVIDIA A100 and RTX 4060 (8GB VRAM); not suitable for CPU-only environments.
- Audio encoder support: Only Chinese HuBERT is fully integrated at launch; wav2vec2 support is pending.
- Mode-image mismatch causes failure: Using
--animation_mode animalon a human photo (or vice versa) produces poor results—ensure alignment. - Custom training is involved: To train your own motion generator, you’ll need a dataset of talking-face videos and must run a multi-step preprocessing pipeline (
01_extract_motions.pythrough04_gen_template.py).
These constraints are typical for research-grade generative models, and the team notes that real-time performance and finer expression control are planned for future work.
Summary
JoyVASA rethinks audio-driven animation by decoupling identity from motion, enabling high-quality, lip-synced videos for both humans and animals from minimal inputs. Its identity-agnostic motion generation, multilingual support, and reusable architecture solve key inefficiencies in prior methods—making it a powerful tool for product teams, researchers, and creators who need expressive, scalable character animation without the overhead of per-character training. With clear documentation, pretrained models, and a simple inference interface, JoyVASA lowers the entry barrier while delivering state-of-the-art visual results.