Deepfake detection is rapidly becoming a critical component of digital trust and media integrity. Yet despite growing interest and investment, the field suffers from a serious but often overlooked problem: the absence of a standardized, unified evaluation framework. Without it, researchers and engineers end up comparing detectors trained on different data pipelines, evaluated with inconsistent metrics, and tested on incompatible dataset splits—leading to misleading conclusions and wasted effort.
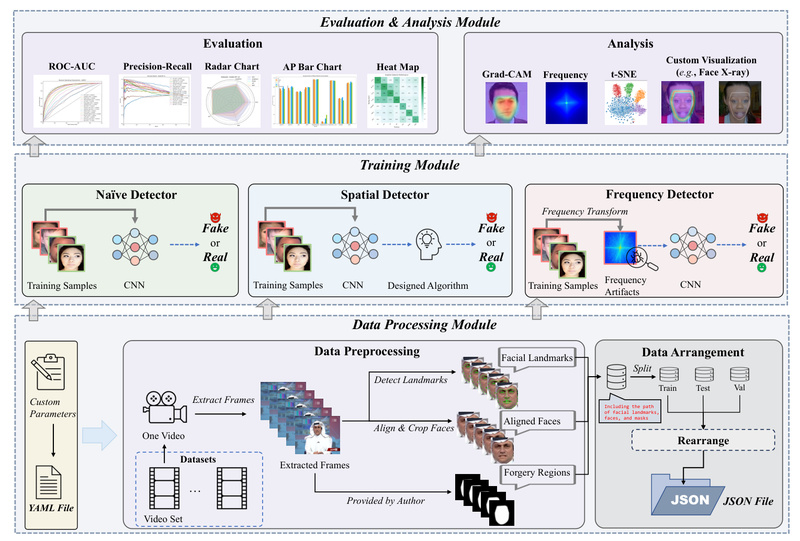
Enter DeepfakeBench, the first comprehensive benchmark designed specifically to solve this fragmentation. Introduced in a NeurIPS 2023 Datasets & Benchmarks paper, DeepfakeBench provides a transparent, reproducible, and extensible platform that ensures all deepfake detectors are evaluated on equal footing. Whether you’re building a new detection algorithm or validating an existing system, DeepfakeBench eliminates guesswork and establishes a common language for performance comparison.
Key Features That Make DeepfakeBench Stand Out
1. Unified Data Management for Consistent Inputs
One of the biggest sources of evaluation bias in deepfake detection comes from variations in data preprocessing—face cropping, alignment, frame sampling, and compression handling differ across studies. DeepfakeBench solves this by offering a standardized data pipeline that processes all datasets uniformly. It includes cropped faces, facial landmarks, and segmentation masks, ensuring every detector receives identical input.
For performance-critical workflows, DeepfakeBench also supports LMDB-based data storage, dramatically accelerating I/O during training and evaluation—especially useful when working with large video datasets.
2. Integrated Framework with 36 State-of-the-Art Detectors
DeepfakeBench isn’t just a dataset—it’s a full-fledged evaluation ecosystem. It currently integrates 36 detection methods, covering:
- 28 image-based detectors, including Xception, EfficientNet-B4, SBI (CVPR 2022), SLADD (CVPR 2022), LSDA (CVPR 2024), and the recently spotlighted Effort (ICML 2025), which detects both face-specific and general AI-generated images.
- 8 video-based detectors, such as I3D, FTCN (ICCV 2021), TALL (ICCV 2023), and VideoMAE (NeurIPS 2022).
Each method is implemented in a modular, plug-and-play fashion, making it trivial to add new detectors or swap backbones. The framework supports both single-GPU experimentation and multi-GPU distributed training via PyTorch’s DDP.
3. Standardized Evaluation Metrics and Protocols
Gone are the days of cherry-picked metrics. DeepfakeBench enforces rigorous, multi-dimensional evaluation, reporting:
- Frame-level and video-level AUC
- Accuracy (ACC) for real vs. fake classification
- Equal Error Rate (EER)
- Precision-Recall (PR) curves and Average Precision (AP)
All evaluations follow consistent train/test splits defined in standardized JSON configuration files, enabling true cross-dataset testing—e.g., training on FaceForensics++ (c23) and evaluating on Celeb-DF, DFDC, or UADFV.
Who Should Use DeepfakeBench—and Why
DeepfakeBench is designed for a wide range of technical decision-makers:
- AI Researchers developing novel detection methods can use it to validate generalizability and compare fairly against 35+ baselines.
- Security Engineers in media, finance, or social platforms can benchmark detector robustness across diverse forgery types and compression levels.
- Product Teams evaluating third-party deepfake detection APIs can use DeepfakeBench to independently verify claims using real-world test protocols.
- Policy & Audit Professionals seeking transparent, reproducible evidence about detection capabilities can rely on its standardized reporting.
Without such a benchmark, teams risk deploying models that appear strong in narrow tests but fail catastrophically in the wild—especially when faced with unseen deepfake generation techniques.
Practical Guide to Getting Started
Getting started with DeepfakeBench is intentionally simple:
- Clone the repository and set up the environment using either Conda (
install.sh) or Docker (recommended for dependency isolation). - Download preprocessed datasets—DeepfakeBench provides ready-to-use RGB or LMDB formats for 9 major datasets, including FaceForensics++, Celeb-DF-v1/v2, DFDC, and UADFV.
- Optionally add the new DF40 dataset, which includes 40 distinct deepfake methods, including the latest state-of-the-art generators.
- Run evaluation in minutes using pre-trained weights (provided for all 36 detectors) with a single command:
python training/test.py --detector_path ./training/config/detector/xception.yaml --test_dataset "Celeb-DF-v2" --weights_path ./training/weights/xception_best.pth
For those training custom models, configuration files (e.g., xception.yaml) allow easy adjustment of datasets, epochs, frame counts, and backbone choices—no code rewriting needed.
Real-World Evaluation Made Easy
DeepfakeBench excels at simulating real-world deployment scenarios through cross-dataset evaluation. For instance, a model trained only on FaceForensics++ can be tested on Celeb-DF, which uses different subjects, lighting conditions, and forgery methods—revealing true generalization ability.
The framework’s rearrangement script automatically generates JSON manifests that unify dataset structures, eliminating the need to write custom data loaders for each new dataset. This not only saves engineering time but also ensures that evaluation conditions remain consistent across experiments.
Moreover, all results are fully reproducible: the same config + weights + data = identical metrics every time. This is critical for scientific rigor and industrial validation alike.
Limitations and Considerations Before Adoption
While powerful, DeepfakeBench has important constraints users should acknowledge:
- Copyright and redistribution: Several included datasets (e.g., Celeb-DF, FaceForensics++) do not have cleared redistribution rights. The project provides processed versions for research convenience, but users must comply with original dataset licenses.
- Pre-cropped faces only: DeepfakeBench assumes faces have already been detected and aligned. It does not model end-to-end pipelines that include face detection—a crucial step in real-world systems. Users must account for this when estimating full-system performance.
- Non-commercial license: The codebase is released under CC BY-NC 4.0, meaning it cannot be used in commercial products without explicit permission from the authors.
These limitations don’t diminish its value as a research benchmark but highlight the need for careful contextual interpretation of results.
Summary
DeepfakeBench is more than a toolkit—it’s a foundational step toward trustworthy, reproducible, and comparable deepfake detection research. By standardizing data, models, and metrics, it removes the noise that has long plagued the field and enables honest progress.
For anyone serious about building, evaluating, or deploying deepfake detectors—whether in academia, industry, or policy—DeepfakeBench offers the only current platform where “apples-to-apples” comparison is not just a slogan, but a technical reality. In an era where synthetic media threatens information integrity, such rigor isn’t optional—it’s essential.