Combinatorial optimization (CO) lies at the heart of countless real-world challenges—from vehicle routing and job scheduling to chip design and cloud resource allocation. While deep reinforcement learning (RL) has emerged as a promising approach to tackle these NP-hard problems without relying heavily on handcrafted heuristics, the field has long suffered from fragmented implementations, inconsistent evaluations, and steep engineering barriers. Enter RL4CO: an open-source, extensive benchmark designed to unify RL-based CO research and development under a single, modular, and production-ready framework.
Built for researchers, engineers, and technical decision-makers alike, RL4CO decouples scientific innovation from infrastructure overhead. It enables rapid prototyping, fair comparison of algorithms, and reproducible experimentation—without requiring teams to rebuild core components from scratch. Whether you’re exploring new policy architectures or deploying an RL solver for logistics planning, RL4CO provides the scaffolding to move faster and with greater confidence.
Why RL4CO Solves a Real Pain Point
Before RL4CO, evaluating or building upon state-of-the-art RL methods for CO often meant sifting through dozens of codebases—each with different conventions, missing documentation, or non-standard environments. This fragmentation slowed progress and made it hard to isolate true algorithmic improvements from engineering artifacts.
RL4CO directly addresses this by offering:
- 27 standardized CO problem environments, including classic benchmarks like the Traveling Salesman Problem (TSP), Capacitated Vehicle Routing Problem (CVRP), and more.
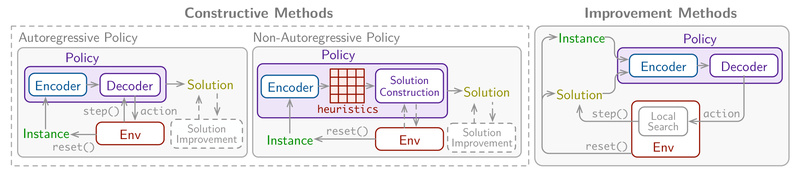
- 23 pre-implemented baselines, covering both constructive (autoregressive and non-autoregressive) and improvement-based policies from recent literature.
- Strict reproducibility: every experiment uses consistent data generation, training loops, and evaluation protocols.
This standardization means you’re no longer guessing whether a method “works”—you can verify it yourself using the same setup the authors used.
Key Technical Capabilities That Save Weeks of Work
RL4CO isn’t just a collection of scripts—it’s a thoughtfully engineered library built on modern PyTorch ecosystem tools:
- TorchRL: for high-performance, GPU-accelerated vectorized environments and RL algorithms.
- TensorDict: to manage heterogeneous data (states, actions, masks, rewards) in a clean, type-safe way.
- PyTorch Lightning: for scalable training with minimal boilerplate.
- Hydra: for flexible, hierarchical configuration management—swap models, environments, or hyperparameters via command line without touching code.
Its modular design lets you mix and match components. For instance, you can plug a new encoder into an existing policy or replace an environment embedding to adapt to a novel problem—all without rewriting core logic. This composability dramatically reduces risk when experimenting or scaling.
Ideal Use Cases: When RL4CO Shines
RL4CO is particularly valuable in the following scenarios:
- Benchmarking new RL algorithms: Need to compare your novel policy against POMO, AM, or NeuRewriter? RL4CO provides drop-in implementations and fair evaluation metrics.
- Prototyping CO solvers: Starting a logistics optimization project? Use RL4CO’s TSP or CVRP environments as a foundation and focus on your domain-specific enhancements.
- Teaching or learning RL for CO: The library’s clear abstractions and minimal examples make it ideal for educational use.
- Hybrid approaches: Combine RL4CO’s learned heuristics with classical solvers (e.g., using RL to guide a local search) without reinventing the data pipeline.
Crucially, RL4CO supports both constructive methods (building solutions step-by-step) and improvement methods (iteratively refining an initial solution)—giving you flexibility based on your problem’s structure.
Getting Started Is Surprisingly Simple
Despite its depth, RL4CO prioritizes usability. Installation is a one-liner:
pip install rl4co
Train a competitive Attention Model on TSP with default settings:
python run.py
Want to switch to CVRP with 100 locations and a custom learning rate? Just override via Hydra:
python run.py experiment=routing/am env=cvrp env.num_loc=100 model.optimizer_kwargs.lr=2e-4
For programmatic control, here’s a complete training script in under 30 lines:
from rl4co.envcs.routing import TSPEnv, TSPGenerator
from rl4co.models import AttentionModelPolicy, POMO
from rl4co.utils import RL4COTrainer
generator = TSPGenerator(num_loc=50, loc_distribution="uniform")
env = TSPEnv(generator)
policy = AttentionModelPolicy(env_name=env.name, num_encoder_layers=6)
model = POMO(env, policy, batch_size=64, optimizer_kwargs={"lr": 1e-4})
trainer = RL4COTrainer(max_epochs=10, accelerator="gpu", precision="16-mixed")
trainer.fit(model)
This level of accessibility means you can go from zero to a trained RL-based optimizer in minutes—not weeks.
Limitations and Practical Considerations
RL4CO is purpose-built for reinforcement learning approaches to combinatorial optimization. It does not replace classical solvers like Gurobi or OR-Tools, which remain superior for problems with small-scale exact solutions or strong mathematical structure.
Users should be comfortable with PyTorch and basic command-line usage. While the library supports GPU acceleration and mixed-precision training, performance gains assume access to modern hardware.
Also note: RL4CO is research-first but designed with production in mind. Integrating it into a live system will require standard engineering practices (e.g., monitoring, fallback strategies), but the core components are stable, tested, and actively maintained by a growing community.
Summary
RL4CO removes the friction that has historically plagued RL-based combinatorial optimization. By providing a unified, well-documented, and extensible benchmark with broad coverage of environments and algorithms, it empowers teams to focus on what matters: innovation, validation, and deployment. If your work involves routing, scheduling, or any discrete optimization challenge where learning-based methods could offer scalability or adaptability, RL4CO is a strategic asset worth adopting today.