Training large language models and vision architectures is notoriously slow, unstable, and expensive. Practitioners routinely face diminishing returns from standard optimizers like AdamW—models converge sluggishly, final performance plateaus early, and hyperparameter tuning becomes a black art. Enter MARS (Make vAriance Reduction Shine): a unified optimizer framework that finally makes variance reduction practical for real-world deep learning.
Unlike previous variance reduction methods that failed to scale beyond toy problems, MARS seamlessly integrates scaled stochastic recursive momentum with adaptive preconditioning. The result? Faster convergence, lower validation loss, and higher downstream accuracy—without increasing compute cost or requiring model redesign. Whether you’re training a GPT-2 from scratch or fine-tuning a vision backbone, MARS delivers consistent, plug-and-play gains over AdamW and newer alternatives like Muon.
Why Standard Optimizers Fall Short in Large-Scale Training
Adaptive optimizers such as Adam and AdamW dominate deep learning for good reason: they’re simple, robust, and require minimal tuning. But as model and data scales grow, their limitations become acute. Stochastic gradients exhibit high variance, causing noisy updates that slow down convergence and hurt generalization.
Variance reduction techniques—long studied in optimization theory—promise to fix this by constructing lower-variance gradient estimates. Yet for over a decade, these methods have struggled to deliver on real neural networks. They often require multiple gradient evaluations per step (doubling compute), introduce instability, or simply underperform AdamW in practice.
MARS bridges this gap. It revives variance reduction not as a theoretical curiosity, but as a practical tool by rethinking how gradient correction and preconditioning interact.
How MARS Works: Best of Both Worlds
At its core, MARS combines two powerful ideas:
- Scaled stochastic recursive momentum: This component generates a variance-reduced gradient estimate by leveraging past gradients on the same batch. Crucially, MARS introduces a scaling factor γ (gamma) that controls the strength of this correction, balancing stability and acceleration.
- Preconditioned updates: Like AdamW or Lion, MARS rescales gradient directions using an approximation of the Hessian (second-order curvature), making updates more informed per dimension.
The update rule is elegantly simple: after computing the corrected gradient cₜ, MARS clips it for stability, feeds it into a momentum buffer, and applies a preconditioned descent step.
Critically, MARS offers an approximate mode (MARS-approx) that computes the gradient correction using only one forward-backward pass per step—making it as efficient as AdamW while still capturing most of the benefits of variance reduction. The exact variant (MARS-exact) uses two passes and yields slightly better results at double the cost, but MARS-approx is recommended for most use cases.
Three Instantiations, One Framework
MARS isn’t a single optimizer—it’s a flexible framework that can be paired with different preconditioners:
- MARS-AdamW: Uses AdamW-style diagonal preconditioning (square root of second-moment estimates). This is the default and best-documented variant.
- MARS-Lion: Leverages sign-based momentum like the Lion optimizer, with preconditioning based on the magnitude of momentum.
- MARS-Shampoo: Employs full-matrix preconditioning via approximate SVD (using Newton-Schulz iterations), suitable for scenarios where higher-order curvature matters.
All three are implemented in a single mars.py file and enabled via the mars_type flag. Note: hyperparameters (especially learning rates) must be tuned separately for each variant—those optimized for MARS-AdamW won’t transfer directly.
Proven Performance Across Language and Vision
MARS isn’t just theoretically sound—it delivers consistent empirical gains:
Language Modeling (GPT-2 Family)
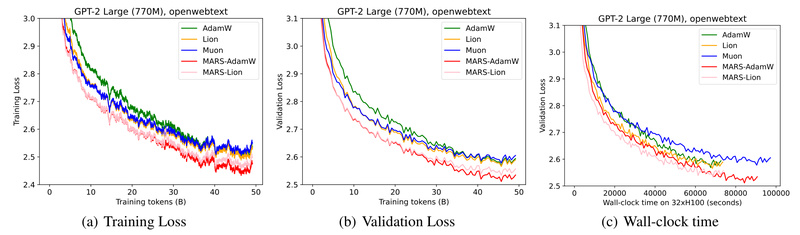
On OpenWebText and FineWeb-Edu, MARS-AdamW consistently beats AdamW and Muon across model sizes:
- GPT-2 Small: Achieves 45.93 average score across 9 benchmarks vs. 45.72 for AdamW.
- GPT-2 XL: Reaches 56.52 HellaSwag accuracy—outperforming AdamW’s 53.93—after training on 50B tokens.
- Validation loss is uniformly lower at every training stage, indicating faster convergence and better final quality.
Vision Tasks (CIFAR-10/100 with ResNet-18)
On image classification, MARS-approx achieves:
- 95.29% test accuracy on CIFAR-10 (vs. 94.81 for AdamW)
- 76.97% on CIFAR-100 (vs. 73.70 for AdamW)
- Lower test loss across the board, demonstrating improved generalization.
These results hold under identical compute budgets, proving MARS isn’t just faster—it’s better.
Getting Started: Plug MARS into Your Training Loop
Adopting MARS requires minimal code changes. Here’s how:
Step 1: Install Dependencies
pip install torch==2.1.2 transformers==4.33.0 datasets tiktoken numpy==1.26.4 wandb
Step 2: Choose Your Variant
In your training script, initialize the optimizer:
from mars import MARS optimizer = MARS( model.parameters(), lr=6e-3, # model-dependent (see table below) betas=(0.95, 0.99), gamma=0.025, # gradient correction strength mars_type="mars-adamw", # or "mars-lion", "mars-shampoo" optimize_1d=False # use AdamW for LayerNorm params if False )
Step 3: Use the Training Loop Template
MARS requires one extra call (update_last_grad()) to store the previous gradient:
for X, Y in data_loader: logits, loss = model(X, Y) loss.backward() optimizer.step(bs=batch_size * seq_len) optimizer.zero_grad(set_to_none=True) optimizer.update_last_grad() # critical for variance reduction
Step 4: Tune Key Hyperparameters
- Learning rate: MARS typically uses 10× higher LR than AdamW (e.g., 6e-3 vs. 6e-4 for GPT-2 Small).
- gamma: Start with 0.025; adjust if training becomes unstable.
- optimize_1d: Keep
Falseinitially; 1D params (biases, LayerNorm) often train better with AdamW.
Full reproduction scripts for GPT-2 Small to XL are included in the repository, making validation straightforward.
Practical Considerations and Limitations
While MARS offers compelling advantages, keep these caveats in mind:
- Hyperparameter sensitivity: Learning rates must be tuned per model size and MARS variant. The repository provides strong starting points, but don’t assume AdamW settings will transfer.
- Architecture scope: Best results are demonstrated on Transformers (GPT-2) and ResNets. Performance on other architectures (e.g., diffusion models, graph nets) isn’t yet validated.
- 1D parameter handling: By default, MARS delegates 1D parameters to AdamW. Enabling
optimize_1d=Truemay require additional tuning. - Compute trade-off: MARS-approx is as efficient as AdamW. Only use MARS-exact if you can afford double gradient computation and need marginal gains.
Summary
MARS solves a long-standing pain point in deep learning: the inability of variance reduction to deliver real-world speedups. By unifying recursive momentum with adaptive preconditioning, it achieves faster convergence, lower loss, and higher accuracy across language and vision tasks—all without increasing compute cost. With drop-in PyTorch integration, multiple variants, and strong open-source support, MARS is a compelling upgrade for any team training large models from scratch. If you’re stuck with AdamW’s limitations, MARS offers a practical path forward.