Retrieval-Augmented Generation (RAG) has become a cornerstone of modern AI applications, enabling systems to answer questions by combining external knowledge with large language models. Yet, evaluating RAG systems remains notoriously difficult. Traditional metrics often treat the RAG pipeline as a black box, failing to distinguish whether performance issues stem from poor retrieval, weak generation, or misalignment between the two. Long-form responses further complicate assessment, while many automated scores show weak correlation with human judgments.
Enter RAGChecker—a purpose-built, fine-grained evaluation framework developed by Amazon Science to diagnose RAG systems with precision. Unlike coarse, end-to-end metrics, RAGChecker decomposes evaluation into interpretable components, offering actionable insights for developers, researchers, and engineering teams aiming to build more robust and reliable RAG applications.
Why RAG Evaluation Needs a New Approach
Standard evaluation practices for RAG often rely on simplistic measures like exact match or ROUGE, which ignore factual grounding, hallucination, or the quality of retrieved context. Worse, they conflate failures: was the answer wrong because the retriever missed the relevant document, or because the generator misinterpreted correct context? Without this distinction, iterative improvement becomes guesswork.
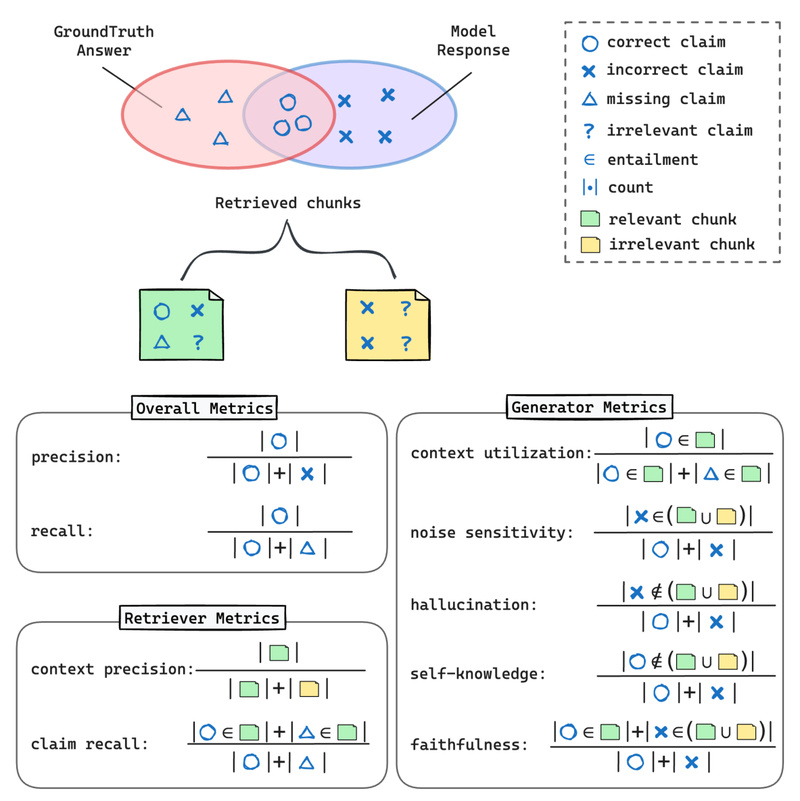
RAGChecker addresses this by introducing modular, claim-level diagnostics. It evaluates not just the final answer, but how well the retriever surfaced relevant facts and how faithfully the generator used them. This approach aligns closely with how humans assess RAG outputs—focusing on correctness, relevance, and faithfulness—and has been validated through extensive meta-evaluation showing significantly higher correlation with human preferences than existing metrics.
Core Capabilities That Set RAGChecker Apart
Holistic Yet Modular Metrics
RAGChecker provides three tiers of evaluation:
- Overall metrics (e.g., precision, recall, F1) give a high-level view of system performance.
- Retriever diagnostics assess whether the retrieved passages contain the necessary facts (e.g., claim recall) and how much noise they include (context precision).
- Generator diagnostics measure how effectively the model uses retrieved context, including faithfulness, hallucination rate, context utilization, and sensitivity to irrelevant or noisy passages.
This structure allows teams to pinpoint weaknesses—e.g., a high hallucination score despite good retrieval suggests a generator that overconfidently invents details.
Claim-Level Entailment for Precision
Instead of comparing entire responses, RAGChecker decomposes generated answers into atomic claims. Each claim is then checked against both the ground truth and the retrieved context using a large language model (e.g., Llama3-70B via AWS Bedrock). This fine-grained approach enables precise attribution of errors and supports nuanced metrics like noise sensitivity—how likely the generator is to be misled by irrelevant retrieved chunks.
Built for Real-World Development
RAGChecker ships with:
- A benchmark dataset of 4,000 questions across 10 domains (released as part of the framework).
- A human-annotated meta-evaluation set to validate metric quality.
- Seamless integration with popular RAG frameworks like LlamaIndex.
These resources reduce setup overhead and ensure evaluations are both reproducible and comparable across studies.
When Should You Use RAGChecker?
RAGChecker shines in scenarios where understanding why a RAG system succeeds or fails is as important as the final score. Ideal use cases include:
- Comparing RAG architectures during prototyping (e.g., dense vs. sparse retrieval, different rerankers).
- Debugging underperforming systems in production by isolating retrieval or generation flaws.
- Validating quality before deployment, especially in high-stakes domains like customer support or technical documentation.
- Benchmarking against published results, using the provided dataset and metrics for apples-to-apples comparisons.
For engineering teams building enterprise RAG applications, RAGChecker transforms evaluation from a final checkpoint into a continuous feedback loop.
Getting Started in Minutes
RAGChecker is designed for easy adoption. Installation requires only two commands:
pip install ragchecker python -m spacy download en_core_web_sm
Input data must follow a simple JSON schema containing, for each query:
- The user query
- Ground truth answer
- Generated RAG response
- List of retrieved context chunks
Once formatted, evaluation can be run via CLI or Python API. For example, using AWS Bedrock-hosted Llama3-70B:
ragchecker-cli --input_path=checking_inputs.json --output_path=checking_outputs.json --extractor_name=bedrock/meta.llama3-1-70b-instruct-v1:0 --checker_name=bedrock/meta.llama3-1-70b-instruct-v1:0 --metrics all_metrics
The output includes detailed scores across all metric categories, enabling immediate analysis. Alternatively, the Python interface offers programmatic control for integration into testing pipelines or CI/CD workflows.
Note that RAGChecker currently relies on external LLMs for claim extraction and verification, which may incur cloud costs or require AWS access. Users can also opt for local models if supported by the underlying RefChecker infrastructure.
Limitations and Practical Notes
While powerful, RAGChecker has important constraints:
- It requires ground truth answers for every query, limiting its use in open-ended or subjective tasks.
- The claim extraction and checking steps depend on capable LLMs, which may introduce latency or cost—especially in joint checking mode (though sequential mode offers a more accurate, albeit slower, alternative).
- RAGChecker is strictly an evaluation and diagnostic tool, not a RAG builder. It complements, but does not replace, RAG development frameworks.
To maximize value, use RAGChecker iteratively—after each major change to your RAG pipeline—to track how architectural choices impact specific failure modes.
Summary
RAGChecker solves a critical bottleneck in RAG development: the lack of trustworthy, interpretable evaluation. By delivering fine-grained, human-aligned diagnostics across both retrieval and generation, it empowers teams to move beyond vague accuracy scores and instead target precise improvements. Whether you’re researching next-generation RAG systems or deploying a customer-facing assistant, RAGChecker provides the clarity needed to build with confidence. The framework is open-source, well-documented, and ready for integration into real-world workflows—making it an essential tool for any serious RAG practitioner.