In modern computer vision workflows, deploying accurate segmentation models often demands large annotated datasets, task-specific architectures, and costly retraining—barriers that slow down innovation, especially in niche domains or fast-moving projects. Matcher changes this paradigm. Introduced in ICLR 2024, Matcher enables zero-training, one-shot segmentation of any object or part using only a single in-context example and off-the-shelf vision foundation models like DINOv2 or SAM. No fine-tuning. No labeled datasets. Just one mask and a new image—and you get precise, context-aware segmentation instantly.
This approach is particularly valuable for practitioners who need rapid, adaptable perception capabilities without the overhead of traditional model development cycles. Whether you’re building a robotics system that must recognize novel tools, an e-commerce platform that detects custom product parts, or a research prototype exploring open-world visual understanding, Matcher provides a lightweight, plug-and-play solution that leverages existing foundation models to their fullest.
Why Matcher Solves Real Pain Points
Traditional segmentation pipelines suffer from three major bottlenecks:
- Data hunger: Most models require hundreds or thousands of labeled examples per class.
- Task rigidity: Switching from semantic to part segmentation—or adapting to a new domain—usually means retraining from scratch.
- Deployment latency: Even with pre-trained models, task adaptation delays product iteration.
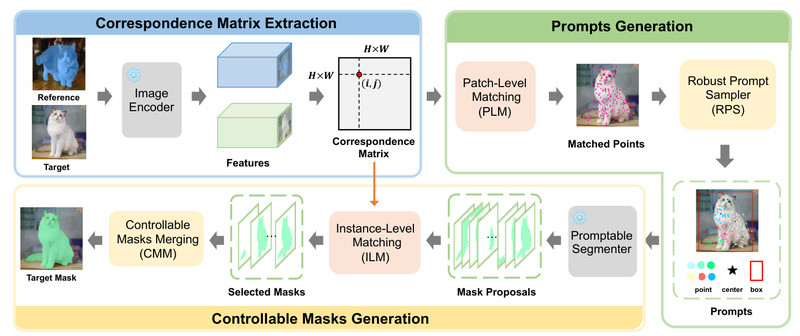
Matcher directly addresses all three. By framing segmentation as a feature matching problem, it uses the rich representations from frozen foundation models and aligns them across images using a single annotated example. This eliminates the need for labeled datasets beyond the one-shot input and removes any requirement for fine-tuning. The result? A system that generalizes across categories, styles, and domains—without ever seeing them during training.
Core Capabilities That Deliver Practical Value
Matcher isn’t just theoretically elegant—it’s engineered for real-world utility. Its standout features include:
One-Shot Semantic and Part Segmentation
Given one image with a human-drawn (or predicted) mask, Matcher can segment the same semantic class or object part in a completely new image—even if that class wasn’t seen during any prior training. This works out-of-the-box with models like SAM and Semantic-SAM.
Cross-Style Generalization
Matcher handles style shifts gracefully. For example, if your example shows a cartoon cat, it can still segment a photorealistic cat in a new image—demonstrating strong open-world adaptability.
Controllable Mask Output
Users can influence the granularity of segmentation—requesting coarse object masks or fine-grained part-level outputs—simply by adjusting the example mask. This level of control is rare in zero-shot systems.
Strong Benchmark Performance Without Training
On COCO-20ⁱ (a one-shot semantic segmentation benchmark), Matcher achieves 52.7% mIoU, outperforming the previous state-of-the-art specialist model by 1.6%. On the more challenging LVIS-92ⁱ benchmark, it hits 33.0% mIoU, surpassing the best generalist model by 14.4%—all without a single gradient update.
Ideal Use Cases for Teams and Projects
Matcher shines in scenarios where speed, flexibility, and minimal data are critical:
- Rapid prototyping: Build proof-of-concept segmentation features in hours, not weeks.
- Domain adaptation: Apply segmentation to medical, agricultural, or industrial imagery without collecting domain-specific labels.
- Niche object handling: In robotics or AR/VR, segment custom tools, furniture parts, or rare objects using just one user-provided example.
- Annotation-efficient workflows: Reduce manual labeling costs by using Matcher to generate high-quality pseudo-labels for downstream tasks.
Because it integrates seamlessly with existing vision foundation models, Matcher can be dropped into current pipelines with minimal engineering effort.
Getting Started: Simple, No-Training Workflow
Using Matcher is straightforward:
- Provide a reference image containing the target object or part, along with a binary mask (drawn manually or from any segmentation tool).
- Input a new query image where you want to segment the same concept.
- Run inference using the open-source Matcher codebase or the provided Gradio demo.
The system leverages pre-extracted features from models like DINOv2 and matches them across images using Matcher’s three core components: a feature alignment module, a mask refinement strategy, and a context-aware aggregation mechanism. No training step is involved at any point.
The GitHub repository includes ready-to-run implementations for one-shot semantic segmentation and one-shot part segmentation, along with dataset preparation guides and demo scripts.
Key Limitations and Practical Considerations
While Matcher offers remarkable flexibility, practitioners should be aware of its current boundaries:
- Video Object Segmentation (VOS) support is planned but not yet released—code and models for VOS are listed as future work in the repository.
- Performance depends on the quality of the underlying foundation model. If the base model (e.g., SAM or DINOv2) fails to capture relevant features, Matcher’s output may degrade.
- Challenging cases—such as highly abstract concepts, low-contrast scenes, or severe occlusions—may yield imperfect masks, as with most zero-shot methods.
These limitations don’t undermine Matcher’s utility but help set realistic expectations for deployment. In many practical settings, especially where even rough segmentation accelerates workflows, Matcher provides immediate value.
Summary
Matcher redefines what’s possible in zero-shot visual perception. By transforming segmentation into a one-shot feature matching task, it eliminates the need for labeled datasets, task-specific architectures, and retraining—enabling practitioners to segment anything, anytime, with just one example. Its strong performance on open-world benchmarks, support for both semantic and part-level tasks, and ease of integration make it a compelling choice for teams seeking agile, annotation-light computer vision solutions. For project leads, researchers, and engineers working under tight timelines or data constraints, Matcher isn’t just an academic novelty—it’s a practical tool ready for real-world adoption.