Large language models (LLMs) like ChatGPT and GPT-4 have transformed how we generate text, write code, solve math problems, and summarize research. But with great fluency comes a hidden risk: factual inaccuracies, or “hallucinations,” that can mislead users, break software, or cite non-existent papers. Manually verifying every output doesn’t scale—especially in production systems, educational tools, or research workflows.
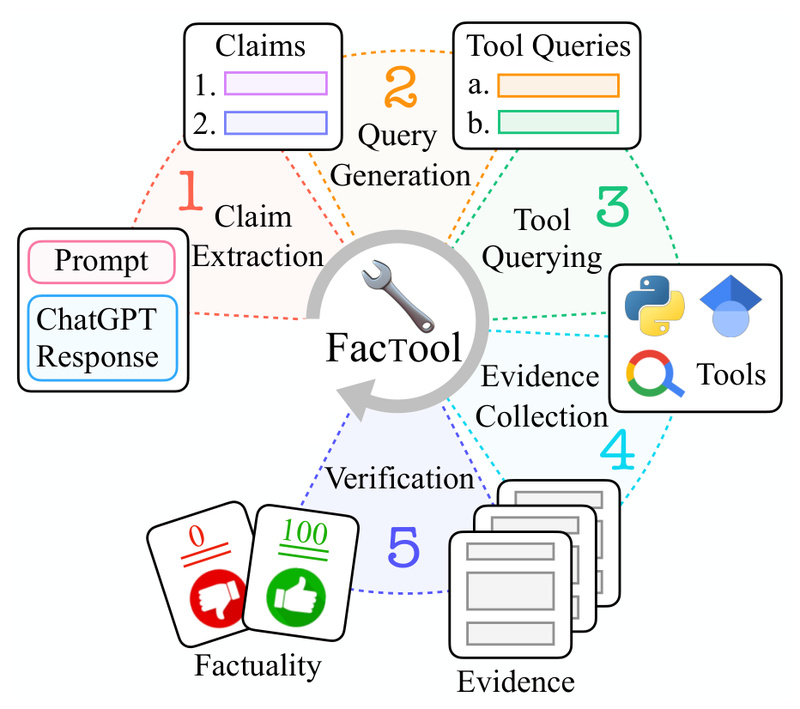
Enter FacTool: a practical, tool-augmented framework designed to automatically detect factual errors in LLM-generated content across four critical domains: knowledge-based question answering, code generation, mathematical reasoning, and scientific literature review. Unlike generic fact-checking methods, FacTool doesn’t just guess—it uses real-world tools like search engines, code executors, and academic databases to verify claims with evidence.
Whether you’re building a trustworthy AI assistant, auditing an LLM’s reliability, or integrating factuality checks into your pipeline, FacTool gives you actionable, structured feedback—down to the claim level—so you know exactly what’s wrong and why.
Why Factuality Matters in Generative AI
As LLMs are deployed in high-stakes scenarios—from customer support chatbots to code co-pilots and academic research assistants—the cost of factual errors rises sharply. A model might confidently state that a researcher works at MIT when they’re actually at Carnegie Mellon. It could generate Python code that looks correct but fails on edge cases. Or it might cite a 2012 paper by authors who never published it.
These aren’t rare edge cases. FacTool’s internal evaluation found that even top models like ChatGPT have response-level factual accuracy below 40% in open-domain knowledge tasks. Without automated verification, such errors go unnoticed until they cause real-world harm.
Manual review is impractical at scale. That’s why a systematic, tool-driven approach like FacTool is essential for responsible AI deployment.
What Is FacTool and How Does It Work?
FacTool is a task- and domain-agnostic framework that treats factuality as a verifiable, evidence-based process. Instead of relying solely on the LLM’s internal knowledge, FacTool breaks down a model’s response into discrete, checkable claims and validates each using external tools best suited to the domain:
- For knowledge-based claims, it uses web search (via Serper) to retrieve real-time evidence.
- For code, it executes the generated snippet against multiple test cases to catch runtime or logical errors.
- For math, it converts reasoning steps into executable Python expressions and evaluates correctness.
- For scientific citations, it queries academic databases (via Scraper API) to verify paper titles, authors, and publication years.
This “tool-augmented” strategy ensures that fact-checking isn’t just linguistic—it’s grounded in observable reality. Crucially, FacTool works without modifying the base LLM, making it easy to plug into existing workflows.
Key Supported Use Cases
FacTool currently supports four high-impact domains, each with unique hallucination risks:
Knowledge-Based QA
Example: An LLM claims, “Graham Neubig is a professor at MIT.”
FacTool’s action: Generates search queries like “Graham Neubig current position,” retrieves evidence from official university pages, and flags the claim as false—correcting it to “Carnegie Mellon University.”
Code Generation
Example: A function meant to count valid triples in an array runs without syntax errors but uses off-by-one indexing.
FacTool’s action: Automatically extracts the entry point, generates test cases, executes the code, and compares outputs against expected behavior—detecting subtle logic bugs.
Mathematical Reasoning
Example: A model calculates “7023116 + 1755779 + 3 + 4 = 8779902.”
FacTool’s action: Translates the arithmetic into a Python expression, executes it, and reveals the sum is actually 8778902—exposing a critical math error.
Scientific Literature Review
Example: An LLM cites “Machine Learning: Trends, Perspectives, and Prospects” by Kamber & Pei (2012).
FacTool’s action: Searches scholarly databases and finds the real paper was authored by Jordan & Mitchell in 2015—marking the citation as hallucinated.
In each case, FacTool doesn’t just say “this is wrong”—it explains why, shows evidence, and often suggests a correction.
How to Get Started with FacTool
Getting started takes minutes:
-
Install via pip:
pip install factool
-
Set API keys (as environment variables):
OPENAI_API_KEY(required for all tasks)SERPER_API_KEY(for knowledge-based QA)SCRAPER_API_KEY(for scientific literature checks)
-
Run a fact-check in Python:
from factool import Factool factool_instance = Factool("gpt-4") inputs = [{"prompt": "Introduce Graham Neubig","response": "Graham Neubig is a professor at MIT","category": "kbqa" }] results = factool_instance.run(inputs) print(results)
The package includes example inputs for all four supported task types, making integration straightforward for developers, researchers, and engineers.
Understanding FacTool’s Output
FacTool returns structured, interpretable results at two levels:
- Claim-level factuality: Each atomic claim is assessed individually, with reasoning, detected errors, supporting evidence, and a boolean verdict.
- Response-level factuality: The entire output is marked as factual only if all claims pass verification.
This granularity lets you identify partial truths (e.g., 1 out of 3 claims is false) and prioritize fixes. Outputs also include generated queries, retrieved evidence URLs, and suggested corrections—ideal for debugging or human-in-the-loop review.
Limitations and Practical Considerations
While powerful, FacTool has important boundaries:
- Domain coverage: It currently supports only four task types. Unsupported domains (e.g., legal reasoning or creative writing) aren’t validated.
- API dependencies: External tools require API keys and may incur usage costs. Offline or private-data scenarios aren’t supported out of the box.
- Claim decomposition: Highly ambiguous or poorly structured responses may lead to incomplete claim extraction, affecting coverage.
- No auto-correction: FacTool detects and explains errors but doesn’t regenerate corrected content—you’ll need to handle fixes separately.
These limitations are transparent and well-documented, enabling informed decisions about where and how to deploy FacTool.
When Should You Use FacTool?
FacTool shines in scenarios where accuracy is non-negotiable:
- AI product teams building user-facing assistants that must avoid spreading misinformation.
- Educational platforms that generate or grade code/math solutions.
- Research labs summarizing literature or benchmarking LLM factuality (FacTool even powers a public Factuality Leaderboard).
- DevOps or MLOps pipelines that require automated validation before deploying LLM-generated artifacts.
If your project involves generating or relying on LLM outputs in any of the four supported domains, FacTool provides a reliable safety net.
Summary
FacTool addresses a critical gap in the generative AI ecosystem: scalable, evidence-based factuality verification. By combining claim decomposition with domain-specific tooling, it delivers precise, explainable error detection across knowledge, code, math, and scientific writing. With minimal setup and clear outputs, it empowers developers and researchers to build more trustworthy AI systems—without waiting for the next “perfect” LLM.
For anyone deploying LLMs in real-world applications, FacTool isn’t just useful—it’s necessary.