Deploying large language models (LLMs) to handle long documents, extensive chat histories, or detailed technical manuals remains a major bottleneck in real-world applications. The root cause lies in the attention mechanism: during the prefill stage, it scales quadratically with sequence length, and during decoding, it consumes massive memory for the key-value (KV) cache. These issues translate directly into slow response times, high infrastructure costs, and scalability limits—especially as context windows expand beyond 32K or even 100K tokens.
Enter LServe, a new high-performance LLM serving system specifically engineered to overcome these challenges. Developed by MIT’s HAN Lab and accepted at MLSys 2025, LServe introduces unified sparse attention—a novel approach that combines hardware-friendly static and dynamic sparsity patterns into a single, efficient inference pipeline. The result? Up to 2.9× faster prefilling and 1.3–2.1× faster decoding compared to vLLM, all while preserving the model’s ability to reason over long contexts accurately.
Unlike methods that require model retraining, architectural changes, or aggressive quantization, LServe works out-of-the-box with standard Llama-family models and integrates seamlessly into existing serving workflows through the OmniServe framework.
Why Long-Context Serving Is Hard—and How LServe Solves It
The Dual Bottlenecks of Long-Sequence Inference
Traditional LLM serving systems face two performance cliffs when handling long inputs:
- Prefill latency explosion: Computing full attention over a 64K-token prompt involves O(n²) operations—easily taking seconds even on top-tier GPUs.
- KV cache memory bloat: Storing full key and value tensors for every token can exhaust GPU memory long before reaching the model’s advertised context limit, forcing batch size reductions or context truncation.
These problems aren’t just theoretical. In production, they manifest as unacceptably slow user experiences or inflated cloud bills when trying to serve enterprise-grade workloads like legal contract analysis or customer support summarization.
LServe’s Core Innovations
LServe tackles both bottlenecks simultaneously through three tightly integrated techniques:
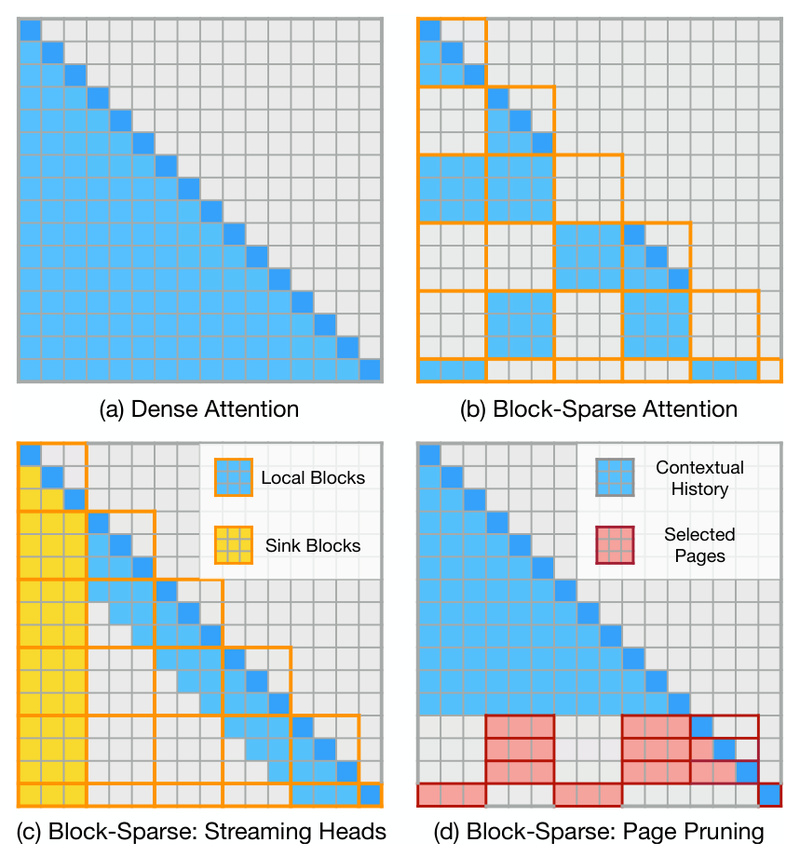
Hybrid Sparse Attention
LServe unifies static sparsity (e.g., block-diagonal or local attention patterns) and dynamic sparsity (query-guided token importance scoring) into a single attention framework. Less relevant tokens are skipped block-wise, drastically reducing compute without harming accuracy. Crucially, this design leverages structured sparsity that aligns with GPU memory access patterns—maximizing hardware utilization.
Streaming Heads
Half of the attention heads are converted into “streaming heads”—low-cost attention variants that only attend to recent tokens or fixed anchors (like the first few tokens). These heads require minimal computation during both prefill and decoding, effectively halving the attention workload for a large portion of the model.
Hierarchical KV Cache Management
Perhaps most surprisingly, LServe demonstrates that only a constant number of KV pages (e.g., 32–64 pages, regardless of whether the context is 8K or 128K tokens) are needed to retain long-context reasoning ability. It implements a query-centric hierarchical selection policy that dynamically prunes irrelevant KV blocks based on similarity to the current query, keeping memory usage stable and predictable.
Together, these optimizations compound multiplicatively—enabling LServe to maintain high throughput even as sequence lengths grow.
Real-World Performance Gains
LServe’s benchmarks speak clearly:
- On Llama-3-8B, LServe achieves 2.9× speedup in prefilling and 1.8× faster decoding versus vLLM on A100 GPUs.
- For MHA-based models like Llama-2-7B, the average end-to-end speedup exceeds 2.0×.
- Accuracy remains intact: LServe passes rigorous long-context evaluations like Needle-in-a-Haystack and LongBench with no degradation compared to dense baselines.
This means teams can finally deploy 100K-token workflows without sacrificing responsiveness or correctness.
Ideal Use Cases
LServe excels in any scenario where input length is both long and variable:
- Legal & compliance: Analyzing full contracts, case law, or regulatory filings.
- Technical documentation: Answering questions over multi-chapter manuals or API references.
- Customer support: Summarizing or routing based on months of chat history.
- Scientific literature: Extracting insights from full research papers or clinical trial reports.
In these cases, traditional systems either throttle performance or truncate context—forcing compromises. LServe removes that trade-off.
Getting Started with LServe
LServe is part of the OmniServe unified inference engine and is straightforward to deploy:
- Install dependencies:
git clone https://github.com/mit-han-lab/OmniServe cd OmniServe conda create -n OmniServe python=3.10 -y conda activate OmniServe pip install -e . pip install flash-attn --no-build-isolation
- Install Block-Sparse Attention: Pre-built CUDA wheels are provided for quick setup (or build from source).
- Run inference:
- End-to-end generation:
bash scripts/lserve_e2e.sh - Benchmarking:
bash scripts/lserve_benchmark/launch.sh
- End-to-end generation:
LServe supports Llama-2, Llama-3, and other MHA-based models out of the box. No model conversion or retraining is needed—just point to your Hugging Face model path.
Limitations and Compatibility
While powerful, LServe has practical boundaries:
- Hardware: Requires modern NVIDIA GPUs (A100, L40S, etc.) with sufficient CUDA core and memory bandwidth.
- Model architecture: Optimized for multi-head attention (MHA) models; not yet validated on MQA or GQA variants.
- Context length threshold: For prompts under 2,000 tokens, sparse attention provides minimal benefit—dense inference may be faster.
- Dependencies: Relies on custom CUDA kernels (Block-Sparse Attention) that must be compiled or installed via provided wheels.
These constraints are typical for cutting-edge inference optimizations and are clearly documented in the repository.
How LServe Compares to vLLM and TensorRT-LLM
| Feature | vLLM | TensorRT-LLM | LServe |
|---|---|---|---|
| Long-context optimization | PagedAttention (memory only) | Limited sparse support | Unified sparse attention + KV pruning |
| Prefill acceleration | ❌ | Partial (via plugins) | ✅ Up to 2.9× |
| Decoding speedup | Baseline | Moderate | ✅ 1.3–2.1× |
| Model changes required? | No | Sometimes | No |
| Accuracy preservation | Full | Full | Full |
LServe doesn’t replace vLLM or TensorRT-LLM—it extends them for the long-context frontier. If your workload regularly exceeds 8K tokens, LServe is the only system delivering both speed and fidelity at scale.
Summary
LServe redefines what’s possible in long-context LLM serving. By unifying sparse attention patterns and intelligently managing the KV cache, it eliminates the traditional trade-off between context length, speed, and accuracy. For teams building applications that demand deep understanding of lengthy documents or histories, LServe isn’t just an optimization—it’s an enabler. With seamless integration into standard workflows and strong performance across Llama-family models, it’s ready for real-world adoption today.