Generating high-fidelity videos with diffusion models has long been bottlenecked by computational inefficiency. Even on powerful GPUs, producing just a few seconds of video can take tens of minutes—making real-time applications, rapid prototyping, or cost-effective deployment nearly impossible. Enter Sparse VideoGen2 (SVG2): a training-free, plug-and-play acceleration framework that slashes inference time by up to 2.3× on leading video diffusion models like HunyuanVideo, Wan 2.1, and Cosmos, without any loss in visual quality or model modification.
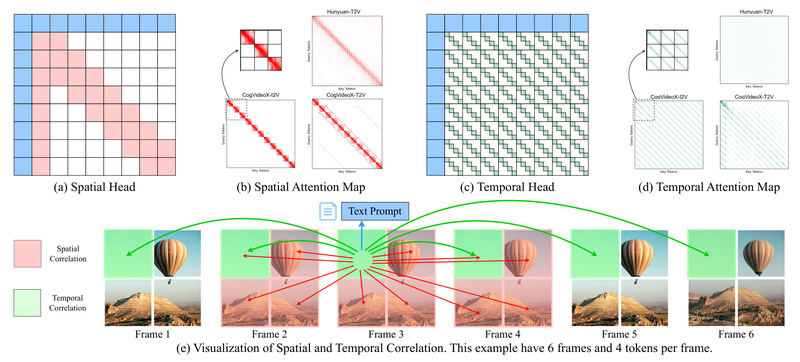
Built on the insight that attention in video diffusion transformers exhibits inherent spatial-temporal sparsity, SVG2 dynamically identifies and exploits this structure during inference. The result? Dramatically faster generation that preserves pixel-level fidelity—exactly what engineers, researchers, and product teams need to make video AI practical.
What Problem Does Sparse VideoGen2 Solve?
Modern video diffusion transformers (DiTs) rely on 3D full attention across space and time. This leads to quadratic computational complexity relative to the total number of tokens—quickly becoming prohibitive as resolution and duration increase. Traditional acceleration methods often require retraining, fine-tuning, or quality compromises.
SVG2 eliminates this trade-off. It operates entirely at inference time, requires zero changes to the original model, and introduces no retraining or distillation. Instead, it leverages the natural sparsity patterns already present in attention maps—something the model implicitly learns but standard implementations waste compute on.
Key Innovations That Drive Performance
Semantic-Aware Sparse Attention
Unlike naive sparsity heuristics, SVG2 introduces semantic-aware token selection. It doesn’t just assume fixed spatial or temporal windows; instead, it dynamically groups tokens based on semantic similarity using an efficient Flash k-Means algorithm (implemented in Triton with >10× speedup over conventional clustering). This ensures only the most relevant tokens participate in attention—reducing wasted computation while maintaining coherence.
Dynamic Attention Kernels & Efficient Layouts
SVG2 co-designs algorithms with hardware. It includes:
- A dynamic attention kernel that adapts to the sparsity pattern per layer and head.
- Hardware-optimized tensor layouts that minimize memory movement.
- Custom fused kernels for RMSNorm, LayerNorm, and Rotary Position Embedding (RoPE), delivering 2.3× to 20× speedups over standard Diffusers implementations—especially at large batch sizes or long sequence lengths.
These aren’t theoretical gains. Benchmarks show 800+ GB/s memory bandwidth on custom kernels versus ~150 GB/s in baseline implementations—directly translating to faster end-to-end generation.
When Should You Use Sparse VideoGen2?
SVG2 shines in scenarios where speed, cost, and quality are all critical:
- Real-time or near-real-time video generation: Reduce latency for interactive applications (e.g., creative tools, gaming, simulation).
- Research prototyping: Iterate faster on video diffusion experiments without waiting hours for generations.
- Production deployment: Cut cloud GPU costs by nearly half—especially valuable when scaling to thousands of users.
- High-resolution workflows: SVG2 supports 720p text-to-video (T2V) and image-to-video (I2V) on models like Wan 2.1 and HunyuanVideo.
If you’re already using these models, SVG2 integrates in minutes—no model surgery required.
Getting Started Is Straightforward
SVG2 is open-source and designed for ease of adoption:
-
Clone the repo (skip large demo files):
GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/svg-project/Sparse-VideoGen.git cd Sparse-VideoGen
-
Set up a compatible environment (Python 3.11–3.12, PyTorch 2.5+/2.6+, CUDA 12.4/12.8).
-
Install dependencies and custom kernels:
conda create -n SVG python=3.12.9 conda activate SVG pip install uv && uv pip install -e . pip install flash-attn --no-build-isolation git submodule update --init --recursive cd svg/kernels && bash setup.sh
-
Run inference with one command—no retraining needed:
# For Wan 2.1 Text-to-Video (SVG2 mode) bash scripts/wan/wan_t2v_720p_sap.sh # For HunyuanVideo bash scripts/hyvideo/hyvideo_t2v_720p_sap.sh
The framework automatically profiles attention sparsity on the fly and applies optimized kernels—transparently accelerating your pipeline.
Limitations and Practical Considerations
While powerful, SVG2 has a few constraints to keep in mind:
- Hardware and software dependencies: Requires modern NVIDIA GPUs (Ampere or newer) and specific CUDA/PyTorch versions.
- Model coverage: Currently supports HunyuanVideo, Wan 2.1, and Cosmos. Support for other DiT-based video models is planned but not guaranteed.
- FP8 attention: Not yet implemented (listed as a future feature).
- Maximum benefit on high-end GPUs: Acceleration is most pronounced on A100/H100-class hardware where memory bandwidth and compute are abundant.
That said, for supported models and environments, SVG2 delivers measurable, production-ready speedups with zero quality degradation.
Summary
Sparse VideoGen2 redefines what’s possible in efficient video generation. By uncovering and exploiting the hidden sparsity in diffusion transformers—through semantic-aware token grouping, dynamic kernels, and system-level optimizations—it achieves >2× faster inference without altering models or sacrificing fidelity. For teams building with HunyuanVideo, Wan 2.1, or Cosmos, SVG2 isn’t just an optimization—it’s a force multiplier that turns impractical generation times into viable workflows.
Best of all: it’s open-source, training-free, and ready to drop into your pipeline today. If you’re serious about scaling video AI, SVG2 deserves a spot in your toolkit.