Lane detection is a foundational capability in autonomous driving and advanced driver-assistance systems (ADAS). Traditional approaches often rely on pixel-wise semantic segmentation, which, while accurate in ideal conditions, becomes computationally expensive and brittle under real-world challenges like heavy occlusions, glare, or low-light scenarios.
Ultra-Fast-Lane-Detection-V2 (UFLDv2) rethinks this problem entirely. Instead of predicting every pixel, it leverages a hybrid anchor–driven ordinal classification framework that dramatically improves both speed and robustness. Built in PyTorch and open-sourced on GitHub, UFLDv2 delivers state-of-the-art accuracy while achieving over 300 frames per second (FPS) in its lightweight configuration—making it uniquely suited for real-time, on-vehicle deployment.
For project and technology decision-makers evaluating perception pipelines, UFLDv2 offers a compelling balance: minimal latency, high reliability in adverse conditions, and a streamlined workflow from training to TensorRT deployment—all without complex post-processing.
Why Traditional Lane Detection Falls Short
Most lane detection models treat the task as dense pixel prediction. This requires high-resolution feature maps and large backbones, leading to:
- High computational cost, unsuitable for edge devices or real-time inference
- Sensitivity to visual degradation, such as shadows, rain, or partial lane occlusion
- Dependency on expensive post-processing (e.g., clustering, curve fitting) to extract usable lane structures
In contrast, human drivers infer lanes using global context—even when only fragments are visible. UFLDv2 mimics this by shifting from pixel-level to coordinate-level prediction using a sparse yet expressive representation.
Core Innovation: Hybrid Anchors + Ordinal Classification
UFLDv2 introduces two key ideas:
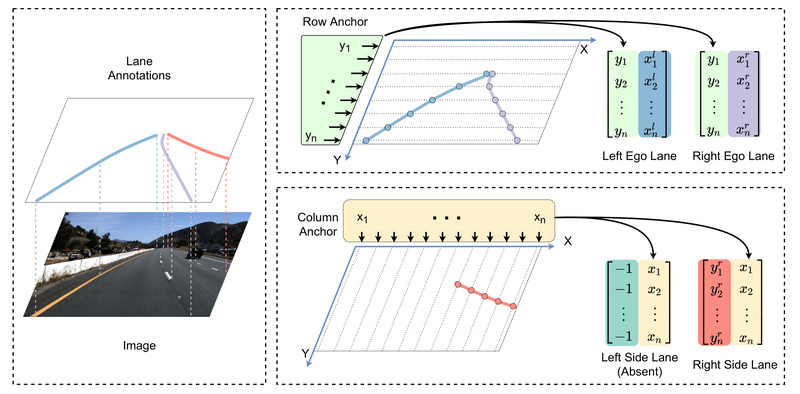
Hybrid Anchor Representation
Instead of dense grids, the model uses a set of predefined anchors—both row-wise and column-wise—that sparsely sample potential lane positions. Each anchor corresponds to a vertical or horizontal slice of the image where a lane point might appear.
This drastically reduces the number of predictions needed. For example, instead of classifying 1600×320 pixels, UFLDv2 may only predict 78 coordinates (e.g., 36 row anchors + 42 column anchors), cutting computational load by orders of magnitude.
Ordinal Classification for Coordinate Regression
Rather than regressing continuous x- or y-coordinates—a task prone to instability—UFLDv2 discretizes the coordinate space and frames lane localization as an ordinal classification problem.
For each anchor, the model predicts which discrete bin the lane point falls into. Because the bins are ordered (e.g., left to right), this preserves spatial relationships while enabling robust training with standard classification losses.
Critically, ordinal classification inherently offers a large effective receptive field, allowing the model to leverage global image context—even when local cues are missing. This explains its strong performance in occluded or poorly lit scenes.
Performance That Stands Out
UFLDv2 has been rigorously evaluated on three major benchmarks:
| Dataset | Backbone | F1 Score | Inference Speed (Lightweight) |
|---|---|---|---|
| CULane | ResNet-18 | 75.0 | >300 FPS |
| TuSimple | ResNet-18 | 96.11 | >300 FPS |
| CurveLanes | ResNet-18 | 80.42 | >300 FPS |
These results demonstrate simultaneous leadership in speed and accuracy—a rare combination in perception models.
Practical Use Cases
UFLDv2 is ideal for:
- Onboard vehicle systems with limited GPU or CPU resources (e.g., embedded NVIDIA Jetson platforms)
- Real-time ADAS features like lane departure warning or adaptive cruise control
- Research prototyping where reproducibility, speed, and robustness are critical
- Scenarios with visual challenges: tunnels, night driving, construction zones, or heavy rain
Because it outputs structured lane coordinates—not segmentation masks—it integrates seamlessly into downstream planning and control modules without additional parsing.
Getting Started Is Straightforward
The project provides clear, modular tooling:
-
Installation: Follow
INSTALL.mdfor environment setup. -
Configuration: Edit
data_rootin a config file (e.g.,configs/culane_res18.py). -
Training:
python train.py configs/culane_res18.py --log_path ./work_dir
(Adjust learning rate by 1/8 for single-GPU training on CULane/CurveLanes.)
-
Evaluation:
python test.py configs/culane_res18.py --test_model model.pth --test_work_dir ./tmp
-
Visualization: Run
demo.pyto overlay predictions on test images. -
Production Deployment: Convert to ONNX, then TensorRT, for ultra-low-latency inference on video streams.
The entire pipeline—from training to embedded deployment—is documented and scriptable, reducing integration risk.
Limitations and Considerations
While UFLDv2 excels in many settings, keep these points in mind:
- Dataset dependency: Performance assumes training on standard benchmarks (CULane, TuSimple, etc.). Domain shifts (e.g., rural roads, non-standard markings) may require fine-tuning.
- Learning rate scaling: Multi-GPU vs. single-GPU training requires manual LR adjustment to maintain convergence.
- Anchor design: The current hybrid anchor layout is optimized for highway-style lanes; extreme curvature or intersection scenarios may need anchor customization.
- Calibration needed: When deploying on new camera setups (different FOV, mounting height), retraining or fine-tuning is recommended for optimal accuracy.
These are typical considerations in any perception system—but UFLDv2’s modular design makes adaptation manageable.
Summary
Ultra-Fast-Lane-Detection-V2 redefines lane detection by replacing pixel-wise segmentation with a sparse, anchor-based ordinal classification framework. The result is a model that is not only fast enough for real-time vehicle systems but also robust enough for real-world driving conditions. With strong benchmark results, clear documentation, and end-to-end deployment support—including TensorRT—UFLDv2 is a practical, high-performance choice for engineers and researchers building next-generation driving assistance and autonomy stacks.
If your project demands low latency, high reliability, and minimal post-processing, UFLDv2 deserves serious consideration.