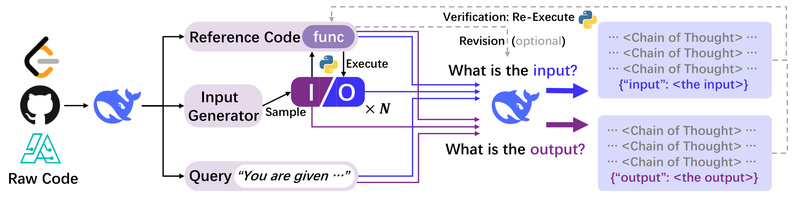
Large language models (LLMs) have demonstrated impressive capabilities in code generation and narrow reasoning tasks like mathematics. Yet, when it comes to general-purpose reasoning—spanning symbolic logic, scientific problem-solving, commonsense inference, and procedural planning—performance often stalls due to fragmented and sparse training data. CodeI/O offers a compelling solution: it leverages the rich, structured reasoning embedded in real-world code not to generate more code, but to teach LLMs how to reason—in natural language—by predicting inputs and outputs from code snippets.
Developed by researchers at HKUST, CodeI/O systematically transforms code into input-output prediction tasks expressed as Chain-of-Thought (CoT) rationales. This approach extracts universal reasoning primitives—such as state-space exploration, decision-tree traversal, modular decomposition, and control-flow planning—while intentionally decoupling them from programming syntax. The result? Models trained with CodeI/O show consistent gains across diverse reasoning benchmarks, from logic puzzles to scientific simulations and everyday commonsense challenges.
What makes CodeI/O especially valuable for practitioners is its built-in verifiability and iterative refinement. Each prediction can be validated either by matching against known outputs or by re-executing the code with predicted inputs. This verification loop enables CodeI/O++, an enhanced version that uses multi-turn revision to correct and improve reasoning chains—leading to higher accuracy and more reliable outputs.
Why CodeI/O Stands Out
Decouples Reasoning from Syntax
Traditional code-generation models conflate procedural logic with language-specific syntax, limiting transferability. CodeI/O deliberately abstracts away Python or C++ constructs and reformulates the task in plain English: “Given this code and its expected behavior, what inputs would produce this output?” or vice versa. This shift allows models to internalize reasoning patterns that apply far beyond programming—making them more adaptable to non-code domains.
Works Across Multiple Reasoning Domains
Empirical results confirm that CodeI/O improves performance not just on coding tasks, but across five key categories:
- Symbolic reasoning (e.g., rule-based systems)
- Scientific reasoning (e.g., simulating physical processes)
- Logical deduction (e.g., constraint satisfaction)
- Mathematical & numerical problem-solving
- Commonsense reasoning (e.g., inferring real-world cause-effect relationships)
This breadth makes CodeI/O uniquely suited for building general-purpose reasoning agents, rather than narrow specialists.
Fully Verifiable Predictions
Unlike standard CoT methods that produce unverifiable explanations, every prediction in CodeI/O can be checked:
- If ground-truth output exists, match directly.
- If not, execute the code using the predicted input and compare results.
This verifiability ensures higher trustworthiness and enables automatic filtering of low-quality generations—critical for deployment in education, research, or safety-sensitive applications.
Iterative Refinement via CodeI/O++
The framework supports a two-stage pipeline:
- Initial prediction of inputs/outputs in natural language.
- Revision round where failed predictions are fed back with error context for refinement.
This multi-turn process—implemented in CodeI/O++—consistently lifts performance, demonstrating that reasoning quality can be improved through structured feedback, much like human learning.
Practical Applications for Technical Teams
CodeI/O isn’t just a research curiosity—it addresses real-world pain points:
- Building robust reasoning agents: For teams developing AI assistants that must reason step-by-step (e.g., in tutoring, diagnostics, or planning), CodeI/O provides a data-efficient way to inject verifiable, generalizable logic.
- Enhancing STEM education tools: Models trained with CodeI/O can explain why a physics simulation behaves a certain way—not just compute it—making them ideal for interactive learning platforms.
- Improving code-assist features: Beyond autocompletion, CodeI/O enables tools that explain code behavior in plain language, helping developers debug or understand unfamiliar codebases.
- Creating high-quality reasoning datasets: The methodology offers a scalable way to harvest procedural reasoning traces from open-source code without being tied to any specific programming language.
Getting Started with CodeI/O
The open-source repository provides a complete pipeline to reproduce or adapt CodeI/O for your own use case. Here’s how it works:
1. Environment Setup
Create a Python 3.11 environment using the provided requirements.txt or environment.yaml. Note that while tailored for Python execution, the framework can be extended to other languages with appropriate runtime support.
2. Data Processing Workflow
The pipeline transforms raw code into reasoning-aligned data in six key steps:
- Unify code format: Convert raw code snippets into structured messages.
- Generate I/O pairs: Execute code to collect input-output examples.
- Build prediction tasks: Frame each sample as a natural-language question (e.g., “What input produces output X?”).
- Initial inference: Use an LLM (via API or local server) to generate predictions.
- Verification: Automatically validate predictions via code re-execution.
- Multi-turn revision (CodeI/O++): Refine incorrect predictions using error feedback.
Scripts for each stage are included, and the repo even provides pre-processed toy data to help you test the flow quickly.
3. Available Resources
- Dataset: The publicly released CodeI/O-PythonEdu-Reasoning subset (due to compliance constraints).
- Pre-trained models: Fine-tuned checkpoints based on Qwen 2.5 7B Coder, LLaMA 3.1 8B, and DeepSeek v2 Lite Coder—available for both CodeI/O and CodeI/O++ stages.
- Training flexibility: Use your preferred framework (e.g., LLaMA-Factory) to train on the generated data.
Limitations and Considerations
While powerful, CodeI/O has practical boundaries:
- Only a subset of the full dataset is public; the complete PythonEdu corpus remains restricted.
- The execution environment is optimized for Python, and extending to other languages may require custom runtime setup.
- The pipeline relies on external LLM APIs (e.g., DeepSeek, GPT-4o-mini) or local inference servers (via vLLM/sglang), which adds infrastructure overhead.
- Best suited for verifiable, procedure-heavy tasks—not for scenarios prioritizing raw code generation speed or stylistic fluency.
That said, for any project where correctness, explainability, and cross-domain reasoning matter more than syntactic code output, CodeI/O offers a principled and effective path forward.
Summary
CodeI/O reimagines code not as an end product, but as a source of universal reasoning patterns. By converting code into natural-language input-output prediction tasks, it equips LLMs with transferable, verifiable, and iteratively improvable reasoning skills. Whether you’re building educational AI, scientific assistants, or general-purpose reasoning engines, CodeI/O provides both the methodology and open-source tooling to elevate your model’s cognitive capabilities—beyond code, and into the realm of robust, human-like reasoning.