In recent years, pre-trained language models (PLMs) have revolutionized natural language processing (NLP), delivering state-of-the-art results across a wide spectrum of tasks. However, many leading Chinese PLMs come with significant computational overhead—large memory footprints, slow inference speeds, and demanding hardware requirements—that make them impractical for real-world applications, especially in resource-constrained environments.
Enter Mengzi, a family of lightweight yet highly capable pre-trained models specifically designed for Chinese NLP. Developed by Langboat, Mengzi strikes a compelling balance between performance and efficiency. It matches or exceeds the accuracy of much heavier models on standard benchmarks like CLUE—while using fewer parameters, enabling faster training and inference, and simplifying deployment. Crucially, Mengzi maintains full architectural compatibility with widely adopted models like BERT and T5, allowing engineers to swap in Mengzi as a direct drop-in replacement—no code refactoring required.
For teams building Chinese-language applications—whether in startups, enterprises, or research labs—Mengzi offers a practical path to high-quality NLP without the infrastructure burden of billion-parameter giants.
Why Mengzi Stands Out
Drop-In Compatibility with Industry Standards
One of Mengzi’s most pragmatic advantages is its seamless integration into existing pipelines. The Mengzi-BERT variants share the exact same architecture as Google’s BERT, meaning you can load Langboat/mengzi-bert-base in Hugging Face Transformers and use it immediately in place of bert-base-chinese or similar models. The same applies to its T5-based models, which align with the T5 v1.1 structure. This compatibility drastically lowers the barrier to adoption—no need to redesign tokenizers, adapters, or fine-tuning scripts.
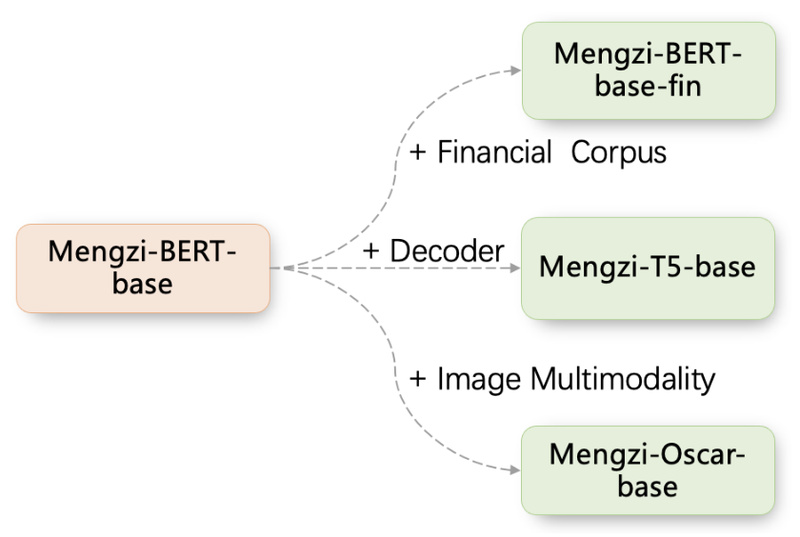
A Diverse Family for Diverse Needs
Mengzi isn’t a single model—it’s a thoughtfully curated suite tailored to different use cases:
- Mengzi-BERT-base (110M): Ideal for classification, named entity recognition (NER), relation extraction, and reading comprehension.
- Mengzi-BERT-L6-H768 (60M): A distilled, ultra-lightweight BERT variant for edge devices or latency-sensitive services.
- Mengzi-BERT-base-fin: A finance-domain-adapted version trained on financial news, reports, and advertisements.
- Mengzi-T5-base (220M): A generative model for controllable text generation tasks like ad copy or news drafting (requires task-specific fine-tuning).
- Mengzi-T5-base-MT: A multi-task T5 model trained on 27 datasets with 301 prompts, enabling zero-shot and few-shot inference across diverse NLP tasks without further training.
- Mengzi-Oscar-base: A multimodal extension for image captioning and vision-language tasks.
- Mengzi-GPT-neo-base and BLOOM-xxx-zh variants: For pure text generation and open-ended writing.
This diversity ensures developers can select the right model for their specific task—avoiding over-engineering while maintaining high performance.
Proven Performance on CLUE Benchmark
Mengzi demonstrates that “lightweight” doesn’t mean “weaker.” On the CLUE benchmark—a comprehensive evaluation suite for Chinese NLP—Mengzi-BERT-base outperforms strong baselines like RoBERTa-wwm-ext across multiple tasks, including:
- CMNLI (natural language inference): 82.12 vs. 80.70
- WSC (Winograd schema): 87.50 vs. 67.20
- CSL (scientific literature classification): 85.40 vs. 80.67
Even the 60M-parameter Mengzi-BERT-L6-H768 holds its own, achieving competitive scores while being nearly half the size of standard BERT.
Practical Use Cases
Mengzi shines in real-world scenarios where speed, cost, and maintainability matter:
- Enterprise NLP Services: Deploy fast, accurate text classification or entity extraction in customer support, compliance, or content moderation systems.
- Domain-Specific Applications: Use Mengzi-BERT-base-fin to process financial documents with minimal fine-tuning.
- Zero-Shot Task Execution: Leverage Mengzi-T5-base-MT to handle unseen tasks via natural language prompts—ideal for rapid prototyping or low-data environments.
- Multimodal Systems: Generate image descriptions or support vision-guided dialogue using Mengzi-Oscar-base.
- Research & Education: Experiment with efficient pre-training strategies or compare lightweight architectures without GPU cluster dependencies.
Because Mengzi models are available on Hugging Face and support both Transformers and PaddlePaddle, they integrate smoothly into both academic and industrial workflows.
Getting Started Is Simple
Loading a Mengzi model takes just two lines of code:
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained("Langboat/mengzi-bert-base")
model = BertModel.from_pretrained("Langboat/mengzi-bert-base")
The same pattern works for T5, GPT-Neo, and BLOOM variants. For PaddlePaddle users, replace transformers with paddlenlp—no other changes needed.
Note that generative models like Mengzi-T5-base are pre-trained only on language modeling and require fine-tuning for specific downstream tasks (e.g., summarization, translation). In contrast, the multi-task Mengzi-T5-base-MT comes ready for zero-shot inference using task-descriptive prompts.
Limitations and Considerations
While Mengzi offers significant advantages, prospective users should be aware of a few constraints:
- Training code is not open-sourced. The team cites internal infrastructure dependencies as the reason, so full reproducibility of training isn’t possible.
- Base generative models need fine-tuning. Unlike instruction-tuned LLMs, Mengzi-T5-base won’t “just work” out of the box for custom generation—task-specific data and training are required.
- Larger BLOOM variants (e.g., 6.4B) still demand substantial memory, though they’ve been pruned for Chinese and optimized for reduced VRAM usage.
- License and liability: The project is released for research use only. The authors disclaim all liability for downstream applications, so production deployments should undergo thorough validation.
These limitations are common among many open pre-trained models, but they’re important to consider during technical planning.
Summary
Mengzi delivers on a critical need in Chinese NLP: high accuracy without the computational bloat. By offering lightweight, benchmark-competitive models that plug directly into existing BERT and T5 workflows, it empowers teams to build efficient, deployable NLP systems—without sacrificing performance. Whether you’re fine-tuning a financial text classifier, prototyping a zero-shot task executor, or exploring multimodal AI, Mengzi provides a lean, practical foundation that’s worth serious consideration.