Detecting human heads in dense, real-world environments—like subway platforms, concerts, or retail stores—is a surprisingly tough problem in computer vision. Many existing object detectors either slow down dramatically under crowd pressure or miss small, partially occluded heads. FCHD (Fully Convolutional Head Detector) directly addresses this trade-off by delivering both speed and solid accuracy in a lightweight, end-to-end trainable architecture. If you need a head detector that runs in near real-time on modest GPU hardware while maintaining reliable performance in crowded scenes, FCHD offers a compelling balance that’s rare among open-source solutions.
What Is FCHD?
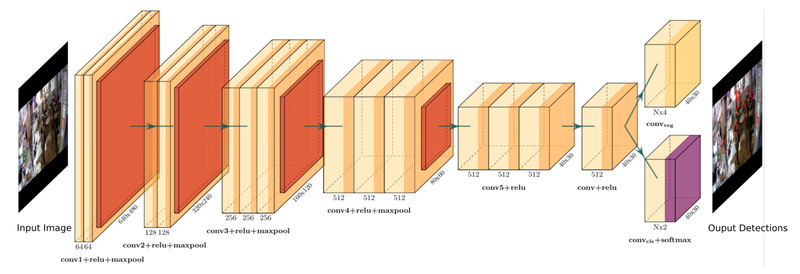
FCHD stands for Fully Convolutional Head Detector. As the name suggests, it’s built entirely from convolutional layers—no region proposal networks, no multi-stage pipelines, and no post-processing heuristics. This design makes it fully end-to-end trainable, with a single network simultaneously handling classification (is this a head?) and regression (where exactly is the bounding box?).
Unlike heavier models that repurpose general-purpose object detectors like Faster R-CNN, FCHD is purpose-built for head detection. It leverages insights from the effective receptive field of its backbone to carefully select anchor box sizes—ensuring better coverage of small heads that commonly appear in crowded scenes. The result? A lean model that avoids unnecessary complexity while staying focused on the task at hand.
Why Head Detection in Crowds Is Hard (And Why FCHD Helps)
In dense scenes, heads can be tiny, overlapping, or partially hidden. Traditional detectors trained on datasets like COCO often fail here because they’re optimized for larger, well-separated objects. Moreover, speed becomes critical when processing live video feeds: a 1 FPS detector is useless for real-time crowd monitoring.
FCHD tackles both challenges:
- Accuracy: It achieves 0.70 average precision (AP) on a challenging head detection benchmark—outperforming earlier methods like OverFeat and ReInspect (under certain configurations) while remaining simpler in design.
- Speed: It runs at 5 FPS on an NVIDIA Quadro M1000M, a mid-range GPU with only 512 CUDA cores, using standard VGA-resolution (640×480) inputs.
This combination makes FCHD particularly valuable for edge or embedded deployments where high-end GPUs aren’t available but real-time responsiveness is non-negotiable.
Key Technical Strengths
1. Lightweight, Single-Stage Architecture
FCHD eliminates the computational overhead of two-stage detectors. Every operation flows through a unified convolutional stream, reducing latency and memory usage.
2. Receptive Field–Aware Anchor Design
Instead of using generic anchor sizes, FCHD calibrates its anchors based on the network’s effective receptive field. This ensures better alignment between feature map locations and actual head scales—critical for detecting small heads in dense crowds.
3. Built on a Proven Backbone
The model uses a VGG16 backbone pre-trained on ImageNet (via Caffe), providing strong transfer learning capabilities without requiring massive custom training from scratch.
4. Straightforward Training and Inference Pipeline
The codebase includes clear scripts for training on datasets like BRAINWASH and running inference on single images. Visualization via Visdom is also supported, helping you monitor training progress easily.
Ideal Use Cases
FCHD excels in scenarios where:
- Crowd density is high, but individual identity isn’t needed (e.g., estimating occupancy in a train station).
- Hardware is limited, such as older GPUs or systems without access to high-end accelerators.
- Real-time feedback matters, like triggering alerts when crowd thresholds are exceeded.
- Resolution is modest, typically VGA or similar—common in legacy surveillance systems.
It’s well-suited for public safety applications, retail foot traffic analysis, or event management—anywhere you need to count or localize heads quickly and reliably without deploying massive models.
Getting Started with FCHD
The project provides a clear workflow:
- Install PyTorch (≥0.4) with GPU support and CuPy.
- Download the pre-trained VGG16 Caffe model and place it in
data/pretrained_model/. - Optionally, download the BRAINWASH dataset for training or fine-tuning.
- Run the demo with your own image:
python head_detection_demo.py --img_path your_image.jpg --model_path checkpoints/head_detector_final
The code includes Cython-based NMS for faster post-processing and integrates Visdom for real-time loss and metric tracking during training.
Important Limitations to Consider
While FCHD offers strong trade-offs, it’s not a universal solution:
- GPU-only: The code does not support CPU inference, limiting deployment on CPU-only edge devices.
- Legacy PyTorch dependency: Built for PyTorch ≥0.4, which may require a dedicated conda environment to avoid compatibility issues with modern libraries.
- Resolution sensitivity: Optimized for VGA inputs; performance may degrade on very high-resolution images unless the model is retrained with adjusted anchors.
- Anchor tuning matters: While the default anchors work well on standard datasets, achieving peak performance on a new domain may require recalibrating anchor sizes based on head scale distributions.
When to Choose FCHD Over Alternatives
Choose FCHD if:
✅ You need a head-specific detector (not a general object detector repurposed for heads).
✅ Your deployment environment has limited GPU resources.
✅ Real-time speed (even at 5 FPS) is more valuable than pushing AP beyond 0.75.
✅ You’re working with standard-definition video feeds in crowded settings.
Avoid FCHD if:
❌ You require CPU-only inference.
❌ You’re targeting state-of-the-art accuracy on modern benchmarks (e.g., newer models like CrowdHuman-optimized detectors may offer higher AP).
❌ Your pipeline depends on recent PyTorch features or libraries incompatible with 0.4-era code.
Summary
FCHD proves that you don’t always need massive models to solve real-world vision problems. By focusing narrowly on head detection, leveraging receptive field insights for anchor design, and maintaining a fully convolutional structure, it delivers a rare blend of speed, accuracy, and deployability—especially in resource-constrained, crowd-heavy environments. For project leads, researchers, or engineers evaluating head detection solutions, FCHD is a practical, well-documented option worth testing against your specific requirements.