Evaluating large language models (LLMs) on new tasks traditionally requires fine-tuning—a process that’s time-consuming, resource-intensive, and often impractical when labeled data is scarce. Enter in-context learning (ICL): a paradigm that leverages a model’s pre-trained knowledge by presenting it with task-specific examples directly in the prompt—no parameter updates needed.
But implementing ICL from scratch is anything but simple. It involves orchestrating data loading, example retrieval, prompt formatting, inference logic, and evaluation—each step demanding careful handling across different models and datasets. That’s where OpenICL comes in.
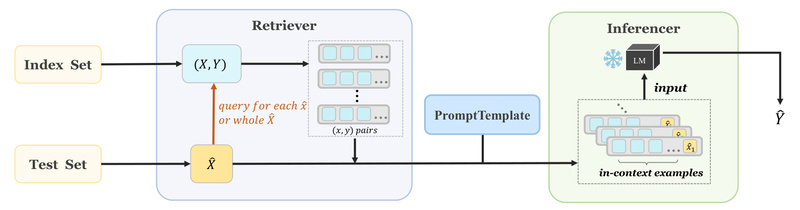
OpenICL is an open-source, research-friendly framework designed to streamline ICL workflows. Built with modularity and flexibility at its core, it lets practitioners and researchers quickly prototype, compare, and evaluate LLMs using state-of-the-art ICL techniques—without rewriting boilerplate code or wrestling with compatibility issues. Whether you’re benchmarking models across NLP tasks or exploring low-resource adaptation strategies, OpenICL removes the friction from in-context learning.
Why OpenICL Solves a Real Pain Point
Many teams struggle with the fragmented, ad-hoc nature of ICL implementations. One project might use custom scripts for retrieving examples; another might hardcode prompt templates or lack support for modern inference methods like self-consistency. This inconsistency slows down experimentation, introduces bugs, and makes replication difficult.
OpenICL addresses this by offering a unified, composable architecture that decouples key ICL components:
- Data handling via standardized dataset readers
- Example retrieval through plug-and-play strategies
- Prompt construction with dynamic templating
- Inference using multiple scoring mechanisms
- Evaluation with built-in metrics
This design means you can swap out a retriever or try a new inference method with minimal code changes—accelerating iteration and ensuring fair comparisons across experiments.
Key Features That Empower Practitioners
1. State-of-the-Art Retrieval Methods Built In
OpenICL includes implementations of proven retrieval strategies like TopkRetriever, which selects the most relevant in-context examples based on input similarity. This eliminates the need to implement your own nearest-neighbor logic or integrate external vector databases for basic use cases.
2. Flexible Prompt Templating
Prompts in ICL aren’t one-size-fits-all. OpenICL’s PromptTemplate class supports both dictionary-based and string-based templates, allowing you to map labels to descriptive instructions (e.g., “Positive Movie Review:”) or inject custom formatting logic. Placeholders like </text> and </E> make it easy to slot in test inputs and retrieved examples cleanly.
3. Multiple Inference Strategies
Not all ICL inference is created equal. OpenICL supports perplexity-based (PPL) inference, where the model’s confidence across candidate outputs determines the prediction. It also includes self-consistency (as of v0.1.8), a technique that aggregates results from multiple sampled reasoning paths to boost accuracy—especially useful for complex tasks like reasoning or semantic parsing.
4. Seamless Hugging Face Integration
Loading datasets is effortless: OpenICL works directly with datasets.Dataset objects from Hugging Face. Just specify input and output column names via DatasetReader, and you’re ready to go—no data wrangling required.
5. Modular, Composable Design
Every component—retriever, template, inferencer, evaluator—is independent. This means you can mix and match them freely. Want to test TopK retrieval with self-consistency on LLaMA? Or compare PPL inference across distilgpt2 and another model? OpenICL’s architecture makes it straightforward.
Ideal Use Cases
OpenICL excels in scenarios where speed, flexibility, and zero retraining are critical:
- Rapid LLM benchmarking: Evaluate multiple models on classification, question answering, machine translation, or semantic parsing tasks using the same ICL pipeline.
- Low-resource prototyping: Test how an off-the-shelf LLM performs on a new domain when labeled data is limited—no fine-tuning needed.
- Research reproducibility: Systematically compare retrieval methods or inference strategies under controlled conditions, with clean separation of concerns.
- Instruction design exploration: Iterate on prompt templates to understand how phrasing affects model behavior, all within a consistent framework.
Because ICL operates entirely at inference time, OpenICL is particularly valuable when compute budgets are tight or when you need to assess a model’s zero-shot adaptability quickly.
Getting Started in Five Steps
OpenICL’s quick-start workflow demonstrates its simplicity. Here’s how it works:
- Load your dataset from Hugging Face or local files using
load_dataset. - Wrap it in a
DatasetReader, specifying which columns contain inputs and labels. - (Optional) Define a prompt template using
PromptTemplateto control how examples and queries are formatted. - Initialize a retriever—like
TopkRetriever—to select in-context examples for each test input. - Run inference with an
Inferencer(e.g.,PPLInferencer) and evaluate results using built-in metrics like accuracy.
The entire pipeline often fits in under 20 lines of code. This developer-friendly structure lowers the barrier to entry while remaining powerful enough for advanced experimentation.
Limitations and Practical Considerations
While OpenICL significantly simplifies ICL, users should keep a few constraints in mind:
- Python 3.8+ required: Ensure your environment meets this baseline.
- Inference-only focus: OpenICL is designed for in-context learning at test time, not for training or fine-tuning.
- Model compatibility: Although it supports models like LLaMA and distilgpt2, not every LLM is guaranteed to work out of the box. Verify compatibility with your target model before scaling.
- Documentation in progress: As noted in the repository, comprehensive docs are still being updated. Users may need to refer to code examples or source files for deeper customization.
Despite these boundaries, OpenICL remains one of the most accessible and extensible toolkits for ICL available today.
Summary
OpenICL removes the implementation overhead that often deters teams from adopting in-context learning. By providing a clean, modular interface for data loading, retrieval, prompting, inference, and evaluation, it empowers researchers and engineers to focus on what to test—not how to code it. Whether you’re evaluating LLMs across diverse NLP tasks or prototyping zero-shot solutions under tight constraints, OpenICL offers a robust, efficient path forward—without a single model update.