FireRedASR is an open-source, industrial-grade automatic speech recognition (ASR) system specifically engineered for Mandarin Chinese—but with strong capabilities in Chinese dialects, English, and even singing lyrics. Designed to bridge the gap between academic benchmarks and real-world deployment, FireRedASR delivers state-of-the-art (SOTA) accuracy while offering flexible model variants to suit different performance, latency, and resource constraints. Whether you’re building a voice assistant for Chinese users, transcribing customer service calls, or integrating speech into an LLM-powered workflow, FireRedASR provides production-ready models that outperform larger, proprietary alternatives.
Two Models for Two Realities: Choose What Fits Your Needs
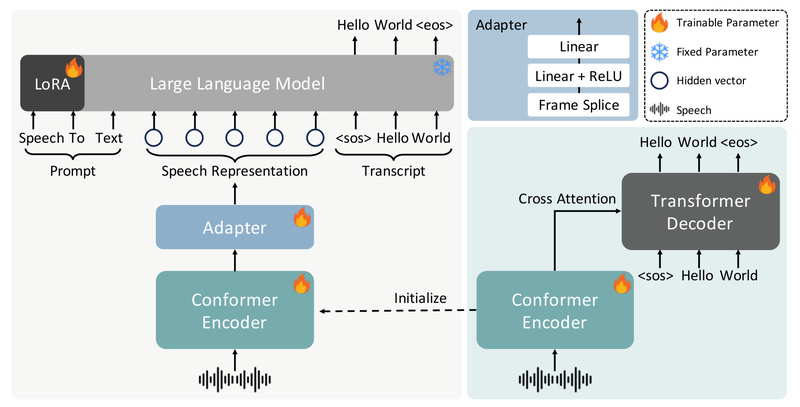
FireRedASR comes in two complementary architectures, each optimized for distinct use cases:
FireRedASR-LLM: Maximum Accuracy with LLM-Powered Understanding
Built on an Encoder-Adapter-LLM framework, FireRedASR-LLM (8.3B parameters) leverages the contextual reasoning power of large language models to deliver end-to-end speech-to-text with exceptional fluency and semantic coherence. This model achieves an average Character Error Rate (CER) of 3.05% across four major Mandarin benchmarks—beating the previous SOTA (3.33%) by an 8.4% relative improvement.
It’s ideal for applications where transcription quality directly impacts user experience, such as intelligent assistants, live captioning, or voice-controlled interfaces in complex domains.
FireRedASR-AED: High Performance with Efficiency
For teams prioritizing inference speed, memory footprint, or edge deployment, FireRedASR-AED (1.1B parameters) uses a classic Attention-based Encoder-Decoder (AED) architecture. Despite its compact size—less than 1/10th the parameters of some competing models—it still achieves a remarkable 3.18% average CER, outperforming models with over 12B parameters.
This makes it perfect as a lightweight speech encoder in multimodal systems or as a standalone ASR engine in resource-constrained environments like mobile apps or embedded devices.
Benchmark Results That Matter in Practice
FireRedASR doesn’t just excel in controlled lab settings—it thrives in messy, real-world audio. On public Mandarin benchmarks including AISHELL-1, AISHELL-2, WenetSpeech (ws_net and ws_meeting), both variants consistently rank at the top:
- FireRedASR-LLM: 0.76% CER on AISHELL-1, 2.15% on AISHELL-2
- FireRedASR-AED: 0.55% on AISHELL-1—among the lowest ever reported
Compared to well-known systems like Whisper-Large-v3, Qwen-Audio, SenseVoice, and Paraformer, FireRedASR achieves significantly lower error rates, especially in challenging scenarios like meetings and live streams. In industrial evaluations across video, live broadcast, and assistant speech, it delivers 24%–40% relative CER reduction over existing baselines—proving its robustness beyond clean read speech.
Beyond Standard Mandarin: Multilingual and Musical Intelligence
While optimized for Mandarin, FireRedASR demonstrates surprising versatility:
- Chinese dialects: Achieves 3.56% CER on KeSpeech (vs. prior SOTA of 6.70%)
- English: Scores 1.73% WER on LibriSpeech test-clean—better than many English-optimized models
- Singing lyrics: Excels at transcribing musical vocals, a notoriously difficult task due to pitch variation, non-standard pronunciation, and background music
This cross-domain competence makes FireRedASR uniquely valuable for media platforms, karaoke apps, podcast transcription, or any application dealing with non-canonical speech.
Developer-Friendly Integration from Day One
FireRedASR is built for adoption, not just publication. The GitHub repository includes:
- Pretrained model weights (FireRedASR-AED-L and FireRedASR-LLM-L)
- Clear setup instructions using Conda and standard Python
- Both command-line tools and Python APIs for flexible integration
- Example scripts for immediate testing
Getting started takes minutes:
# Transcribe with AED speech2text.py --wav_path audio.wav --asr_type "aed" --model_dir pretrained_models/FireRedASR-AED-L # Or use the LLM variant speech2text.py --wav_path audio.wav --asr_type "llm" --model_dir pretrained_models/FireRedASR-LLM-L
In Python, the FireRedAsr class abstracts complexity while exposing key decoding parameters like beam size, length penalty, and repetition control—enabling fine-tuned behavior without deep ASR expertise.
Real-World Use Cases Where FireRedASR Delivers Value
- Voice assistants for Chinese-speaking markets: Leverage FireRedASR-LLM’s LLM integration for natural, context-aware responses.
- Customer service analytics: Transcribe call center recordings with high accuracy across accents and background noise.
- Video subtitling & content indexing: Process hours of user-generated video with reliable Mandarin recognition.
- Multimodal LLM pipelines: Use FireRedASR-AED as a compact, high-quality speech encoder in larger AI systems.
- Music and entertainment apps: Accurately transcribe lyrics from songs—a niche capability few ASR systems handle well.
Operational Considerations and Limitations
To ensure reliable performance, keep these constraints in mind:
- FireRedASR-AED supports audio up to 60 seconds. Inputs longer than 200 seconds may trigger positional encoding errors; beyond 60s, hallucination risks increase.
- FireRedASR-LLM is limited to ~30 seconds of input audio. Behavior on longer utterances is undefined.
- For batch inference with FireRedASR-LLM, avoid mixing very short and very long utterances in the same batch—this can cause repetition artifacts. Either sort by duration or use
batch_size=1for mixed-length inputs.
These guidelines help you avoid common pitfalls during deployment.
Summary
FireRedASR redefines what’s possible in open-source Mandarin ASR. By combining industrial-grade robustness, SOTA accuracy, multilingual support, and singing transcription—all while offering both LLM-enhanced and lightweight variants—it addresses real engineering trade-offs faced by developers and researchers. With full source code, pretrained models, and clear documentation available on GitHub, FireRedASR lowers the barrier to building high-quality, Mandarin-first voice applications without vendor lock-in or hidden costs. If your project involves speech in Chinese contexts, FireRedASR deserves a serious look.