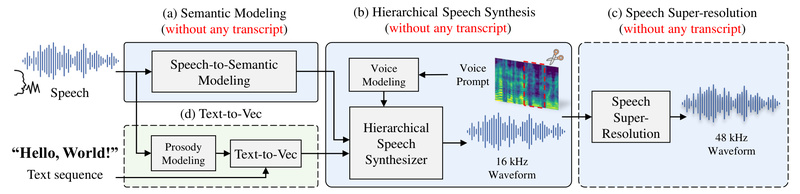
In the rapidly evolving field of speech synthesis, achieving natural-sounding, speaker-consistent voice generation without speaker-specific training data has long been a major challenge. Enter HierSpeech++—a breakthrough zero-shot text-to-speech (TTS) and voice conversion (VC) system that delivers human-level speech quality, robust speaker similarity, and fast inference, all without requiring fine-tuning on target speakers.
Unlike large language model (LLM)-based or diffusion-based alternatives that suffer from slow generation speeds or inconsistent voice fidelity, HierSpeech++ leverages a hierarchical variational inference framework to bridge semantic and acoustic representations of speech efficiently. Whether you’re building a multilingual voice assistant, prototyping a voice-cloning app, or researching expressive TTS, HierSpeech++ offers a production-ready solution that balances speed, quality, and flexibility—making it one of the most practical zero-shot synthesizers available today.
Why HierSpeech++ Stands Out
Zero-Shot Performance That Feels Human
HierSpeech++ excels in zero-shot scenarios, meaning it can synthesize speech in the voice of a speaker it has never seen during training—using only a short reference audio clip (the “voice prompt”). Remarkably, user studies and objective evaluations show it achieves human-level naturalness and speaker similarity, a milestone rarely matched by other models. This makes it ideal for applications where collecting speaker-specific data is impractical or impossible.
Speed Without Sacrificing Quality
Many modern TTS systems based on LLMs or diffusion models are notoriously slow—some taking minutes to generate seconds of speech. HierSpeech++, in contrast, uses a GAN-based end-to-end architecture that enables real-time or near-real-time inference. This speed advantage is critical for interactive applications like virtual agents, live voice dubbing, or on-device TTS.
Built-In Expressiveness via Prosody and F0 Control
Natural speech isn’t just about words—it’s about rhythm, pitch, and emotional tone. HierSpeech++ incorporates explicit modeling of fundamental frequency (F0) and prosody through a text-to-vector (TTV) module. This module converts text into rich semantic and prosodic representations, which the synthesizer then uses to generate expressive, contextually appropriate speech—without manual scripting or post-processing.
High-Fidelity Audio with Super-Resolution
Out of the box, HierSpeech++ generates 16 kHz speech, but it includes a lightweight Speech Super-Resolution (SpeechSR) module that upsamples audio to 24 kHz or even 48 kHz. This delivers studio-quality output suitable for audiobooks, media production, or broadcast—without requiring separate post-generation enhancement tools.
Robustness Across Diverse Inputs
Thanks to its hierarchical design and noise-controllable inference, HierSpeech++ handles a wide range of prompts and text inputs reliably. Users can tune the noise_scale parameter:
- 0.333 for maximum robustness (ideal for clear, consistent output)
- 0.667 for greater expressiveness (useful for dynamic or emotional delivery)
Additionally, a built-in denoising option helps clean noisy reference prompts, further improving voice conversion stability.
Practical Use Cases
HierSpeech++ shines in real-world scenarios where flexibility, speed, and voice fidelity are non-negotiable:
- Instant Voice Cloning: Create personalized voice assistants or customer service bots using just a 5–10 second audio clip of a target speaker—no retraining needed.
- Multilingual TTS Prototyping: With support for English and Korean (and multilingual TTV-v2 in development), teams can rapidly test voice experiences across languages.
- Cross-Lingual Voice Conversion: Convert speech from one language into another while preserving the original speaker’s voice identity—valuable for dubbing or accessibility tools.
- Research & Product Development: Startups and academic labs benefit from pre-trained models and simple inference scripts, accelerating experimentation without massive compute investment.
Getting Started Is Simple
You don’t need to train from scratch to use HierSpeech++. The project provides:
- Pre-trained models for TTS (TTV-v1), voice synthesis (HierSpeech++ backbone), and super-resolution (SpeechSR-24k/48k)
- Straightforward inference scripts (
inference.shfor TTS,inference_vc.shfor voice conversion)
A typical TTS command looks like this:
python3 inference.py --ckpt "logs/hierspeechpp_eng_kor/hierspeechpp_v1.1_ckpt.pth" --ckpt_text2w2v "logs/ttv_libritts_v1/ttv_lt960_ckpt.pth" --output_dir "results" --noise_scale_ttv 0.333 --noise_scale_vc 0.333 --denoise_ratio 0.8 --output_sr 48000
This generates high-fidelity, 48 kHz speech with balanced robustness and clarity—ready for deployment or evaluation.
Limitations and Workarounds
While HierSpeech++ sets a new bar for zero-shot synthesis, it’s important to understand its current boundaries:
- Input Length Limit: Training data was filtered to sentences under ~12 seconds (
wav_max = 600frames), so very long utterances may degrade in quality. Workaround: Break long texts into shorter segments. - Training Complexity: Full training is slower than lightweight models like VITS and requires significant GPU memory. However, inference remains fast, and pre-trained checkpoints eliminate the need for most users to train from scratch.
- Voice Conversion Sensitivity: Noisy reference prompts can lead to inaccurate pitch (F0) extraction, affecting output quality. Mitigation: Use the built-in MP-SENet denoiser (enabled via
--denoise_ratio) or provide clean reference audio. - Training Code Availability: As of now, only inference and TTV-v1 training code are public; full training pipelines for the synthesizer and SpeechSR will follow after paper acceptance.
These are manageable trade-offs given the system’s overall performance—and the team is actively addressing them in ongoing work like TTV-v2, which promises better long-form synthesis and multilingual support.
Summary
HierSpeech++ redefines what’s possible in zero-shot speech synthesis. By combining hierarchical variational inference, explicit prosody modeling, and efficient super-resolution, it delivers fast, natural, and speaker-consistent speech without speaker-specific data. For developers, researchers, and product teams seeking a reliable, high-quality TTS/VC solution that works out of the box, HierSpeech++ is not just an alternative—it’s a new standard.
With open-source code, pre-trained models, and simple inference workflows, getting started has never been easier. Whether you’re building the next voice-enabled app or pushing the boundaries of speech AI research, HierSpeech++ gives you the tools to do it—quickly, clearly, and convincingly.