In today’s fast-moving landscape of open-source large language models (LLMs), developers and researchers are increasingly faced with a dilemma: dozens of specialized models exist—each excelling at coding, reasoning, dialogue, or domain-specific tasks—but none offer a truly general-purpose capability out of the box. Retraining or fine-tuning from scratch is expensive, data-intensive, and often impractical.
Enter MergeKit: an open-source, hardware-efficient toolkit that lets you combine multiple pre-trained LLMs directly in weight space—without any additional training or access to original datasets. By intelligently merging model parameters, MergeKit enables you to create versatile, high-performing models that retain the strengths of their sources while avoiding pitfalls like catastrophic forgetting. Best of all, it runs on modest hardware—even a CPU or GPU with just 8 GB of VRAM—and has already powered some of the top-ranked models on the Open LLM Leaderboard.
Why Merge Models at All?
Traditional approaches like ensembling require running multiple models simultaneously, drastically increasing inference latency and cost. Fine-tuning a base model on multiple tasks often leads to catastrophic forgetting, where the model loses previously acquired knowledge.
Model merging sidesteps both issues. Instead of training, you operate directly on model weights to blend capabilities. For example:
- Fuse a code-specialized Llama variant with a math-reasoning Mistral model to get a single model strong in both areas.
- Combine several instruction-tuned checkpoints to create a robust generalist assistant.
- Transfer stylistic or formatting behaviors (e.g., ChatML or Llama 3 chat templates) between models without data.
The result? A single, efficient model that performs like an ensemble but runs like a base model—ideal for deployment, experimentation, or rapid prototyping.
Key Capabilities That Set MergeKit Apart
MergeKit isn’t just another model combiner—it’s a full-fledged framework designed for flexibility, efficiency, and innovation.
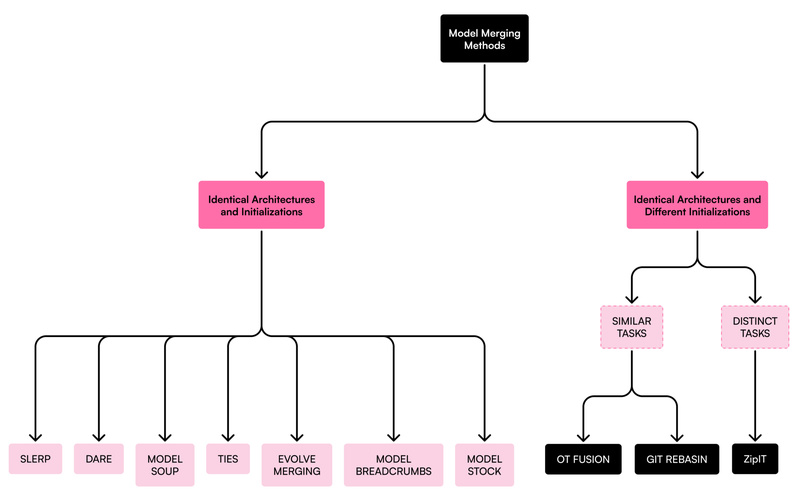
Dozens of Proven Merge Strategies
MergeKit supports a wide array of merging algorithms, each suited to different scenarios:
- Linear averaging for simple model soups.
- SLERP (Spherical Linear Interpolation) for smooth transitions between two models.
- TIES and DARE, which use sparsification and sign consensus to reduce interference when merging many fine-tuned models.
- Task Arithmetic, which treats fine-tuned models as “task vectors” relative to a base model and combines them like algebraic operations.
- Passthrough (“Frankenmerging”), which lets you stack layers from different models—e.g., take early layers from one model and later layers from another.
These methods are not theoretical—they’re battle-tested by the community and documented in peer-reviewed research.
Runs Anywhere, Even on Limited Hardware
Thanks to its out-of-core, lazy tensor loading architecture, MergeKit minimizes memory usage. You can merge billion-parameter models on a laptop with no GPU, or accelerate the process with as little as 8 GB of VRAM. This democratizes advanced model composition for individual researchers and small teams.
Advanced Tooling for Real-World Use
Beyond basic merging, MergeKit offers specialized utilities:
- LoRA extraction: Distill a fine-tuned model into a low-rank adapter for efficient reuse.
- Mixture-of-Experts (MoE) creation: Convert multiple dense models into an MoE architecture for scalable inference.
- Tokenizer surgery: Seamlessly merge vocabularies and preserve critical tokens (like
<|im_start|>