Building truly natural voice interfaces has long been a holy grail in AI—yet most current systems fall short when it comes to fluid, human-like conversation. Traditional full-duplex voice agents rely on complex pipelines: voice activity detectors, interrupt handlers, conversation state trackers, or even multiple language models working in tandem. These modular architectures suffer from error propagation, latency, and an inability to handle nuances like timely interruptions, overlapping speech, or real-time echo cancellation.
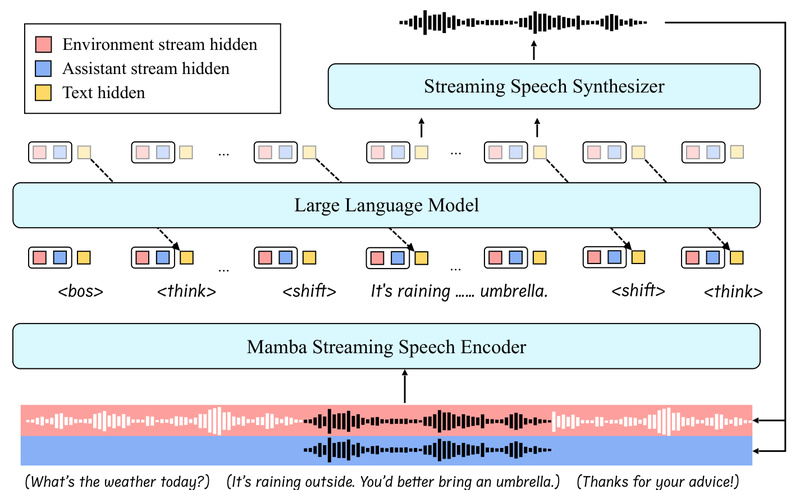
Enter SALMONN-omni, a breakthrough from ByteDance that reimagines how speech-language models should work. Unlike prior approaches—including recent ones like Moshi that inject audio codecs into the LLM’s token stream—SALMONN-omni operates without any audio codecs in its token space. It is the first standalone, full-duplex speech large language model that processes raw speech directly while maintaining a single, unified architecture.
At its core, SALMONN-omni introduces a dynamic thinking mechanism embedded within the LLM backbone. This innovation allows the model to autonomously decide when to listen, when to speak, and when to yield the floor—mimicking the turn-taking behaviors of human dialogue. The result? A conversational AI that doesn’t just respond to prompts, but actively participates in real-time, bidirectional speech interactions.
Why Full-Duplex Matters—and Why Most Systems Fail
Many voice assistants today operate in half-duplex mode: you speak, it listens; it speaks, you wait. This feels robotic and inefficient, especially in dynamic scenarios like customer support, in-car assistants, or collaborative AI agents. True full-duplex conversation—where both parties can talk and listen simultaneously—requires solving several hard problems:
- Context-dependent barge-in: Can the system recognize when a user legitimately interrupts (e.g., “Wait, that’s not what I meant!”) versus accidental overlap?
- Backchanneling: Can it produce subtle verbal cues like “uh-huh” or “I see” to show active listening without taking over the conversation?
- Echo cancellation: When speaking, can it avoid “hearing” its own voice and misinterpreting it as user input?
- Seamless turn-taking: Can it detect natural pause points and respond at the right moment—not too early, not too late?
Most open-source systems either ignore these challenges or patch them with external modules, which introduces fragility and latency. SALMONN-omni learns these behaviors end-to-end through its dynamic thinking mechanism, trained on conversational speech data and further refined via reinforcement learning.
Performance That Defies Data Constraints
One of the most compelling aspects of SALMONN-omni is its efficiency. Despite using substantially less training data than many competitors, it achieves over 30% relative improvement on standard benchmarks for spoken question answering and open-domain dialogue compared to existing open-source full-duplex models.
Even more impressively, it performs on par with turn-based or half-duplex systems—which have the luxury of simplified interaction flows—while operating under far more demanding real-time, full-duplex conditions. This suggests that architectural innovation (like codec-free design and dynamic state control) can outweigh brute-force data scaling.
For developers and researchers, this means high-quality conversational performance is achievable without massive datasets or complex multi-component pipelines—a significant reduction in engineering overhead and infrastructure cost.
Ideal Applications for SALMONN-omni
SALMONN-omni isn’t just a research curiosity; it’s built for real-world deployment in scenarios that demand responsiveness and conversational fluency:
- Voice assistants that handle interruptions gracefully (e.g., smart speakers, mobile voice UIs).
- Customer service bots that can manage overlapping speech, confirm understanding with backchannels, and switch roles naturally.
- Collaborative AI agents in productivity or gaming environments where timing and presence matter.
- Accessibility tools that require low-latency, natural speech interaction for users with motor or visual impairments.
Crucially, SALMONN-omni is not a general-purpose text LLM with speech input tacked on. It is purpose-built for conversational speech, optimized for the temporal, interactive, and acoustic complexities of real dialogue.
Getting Started and Practical Considerations
The model and inference code are available in the official GitHub repository: https://github.com/bytedance/SALMONN. While the project provides checkpoints and demo scripts, it’s important to note that SALMONN-omni is currently a research-grade model. Deploying it in production may require:
- Adequate GPU/TPU resources for real-time inference.
- Fine-tuning on domain-specific dialogue data (e.g., for healthcare or finance).
- Integration with existing audio I/O pipelines, though its standalone nature simplifies this compared to modular alternatives.
Since it does not rely on external codec tokens or auxiliary models, integration is conceptually cleaner—but developers should still validate performance on their target use cases, especially regarding latency and acoustic robustness.
Summary
SALMONN-omni represents a significant leap toward truly natural voice AI. By eliminating audio codecs from the token space and embedding a dynamic thinking mechanism directly into the LLM, it delivers fluid, full-duplex conversation capabilities that outperform existing open-source alternatives—even with less training data. For teams building next-generation voice interfaces, SALMONN-omni offers a streamlined, high-performance foundation that tackles the core challenges of real-time spoken dialogue head-on.