MiMo is a 7-billion-parameter language model purpose-built for reasoning-intensive tasks—spanning mathematics, code generation, and STEM problem solving—without the computational overhead of much larger models. What sets MiMo apart isn’t just its compact size, but its end-to-end optimization from pretraining through post-training. Unlike conventional approaches that treat reasoning as an afterthought, MiMo integrates reasoning-centric strategies at every stage of its development, enabling it to surpass 32B-class models and even rival OpenAI’s o1-mini in key benchmarks. For teams and researchers working under tight compute or latency constraints, MiMo offers a rare combination: top-tier reasoning performance in a lightweight, deployable package.
Why MiMo Delivers Exceptional Reasoning in a Small Footprint
Most state-of-the-art reasoning models rely on large parameter counts—often 32B or more—to achieve competitive results in math and code. MiMo challenges this norm by proving that architectural ingenuity and data-centric design can unlock superior reasoning capabilities even in a 7B model. Central to this achievement is a holistic training philosophy: MiMo isn’t just fine-tuned for reasoning—it’s born for it.
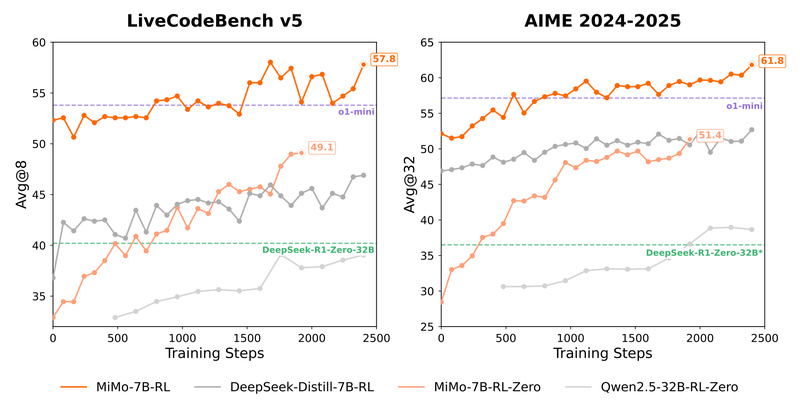
The result? MiMo-7B-RL, the final reinforcement learning (RL)-tuned version, achieves 95.8% Pass@1 on MATH500 and 68.2% on AIME 2024—outperforming many larger open-source models and closely matching o1-mini. In code evaluation, it scores 57.8% on LiveCodeBench v5, leading among 7B models and competing with models twice or thrice its size. This makes MiMo particularly attractive for applications where inference cost, speed, and reliability matter—such as educational tools, coding assistants, and scientific reasoning pipelines.
Pretraining Engineered for Reasoning Potential
MiMo’s foundation—MiMo-7B-Base—was trained from scratch with a singular focus: maximizing inherent reasoning capacity. This starts with data. The pretraining corpus spans 25 trillion tokens and is curated using a three-stage data mixing strategy that progressively introduces higher-quality, reasoning-dense content.
Key innovations include:
- Enhanced data preprocessing: Improved text extraction and multi-dimensional filtering to retain logic-rich content while discarding noise.
- Synthetic reasoning data generation: Large-scale creation of diverse, high-quality synthetic problems to enrich pattern exposure during pretraining.
- Multi-Token Prediction (MTP): An auxiliary training objective that predicts multiple future tokens simultaneously. MTP not only boosts reasoning performance but also accelerates inference by enabling speculative decoding with ~90% token acceptance rates.
Together, these techniques ensure that the base model enters post-training with exceptional latent reasoning ability—so much so that MiMo-7B-Base alone outperforms many 32B models on reasoning benchmarks.
Post-Training: Reinforcement Learning That Works for Math and Code
Post-training is where many models falter—especially in reasoning domains where reward signals are sparse and evaluation is non-differentiable. MiMo tackles this with a meticulously designed RL pipeline built around three pillars:
- High-quality, verifiable RL data: A dataset of 130K math and programming problems, each cleaned, difficulty-rated, and automatically verifiable via rule-based executors. This eliminates reliance on imperfect proxy rewards and prevents reward hacking.
- Test-difficulty-driven code reward: Instead of binary pass/fail signals, MiMo assigns fine-grained scores based on the difficulty of individual test cases. Harder cases yield higher rewards, providing dense, informative gradients that guide policy improvement even on complex problems.
- Strategic data resampling: During later RL stages, easy problems are resampled more frequently to stabilize training and improve rollout efficiency—avoiding the common pitfall of policy collapse on hard examples.
This approach yields MiMo-7B-RL, a model that not only excels quantitatively but also demonstrates robust, consistent reasoning behavior across diverse problem types.
Real-World Benchmarks: Where MiMo Shines
MiMo’s performance has been rigorously validated across multiple domains:
- Mathematics:
- MATH500: 95.8% (Pass@1)
- AIME 2024: 68.2%
- AIME 2025: 55.4%
- Code:
- LiveCodeBench v5: 57.8%
- LiveCodeBench v6: 49.3%
- STEM & General Reasoning:
- GPQA-Diamond: 54.4%
- MMLU-Pro: 58.6
Notably, MiMo-7B-RL matches or exceeds OpenAI o1-mini on math and code while maintaining a fraction of the size. The newer MiMo-7B-RL-0530 variant pushes this further—reaching 80.1% on AIME 2024, surpassing DeepSeek R1.
All evaluations use temperature=0.6, reflecting real-world usage rather than cherry-picked settings.
Easy Integration with Standard Inference Stacks
Adopting MiMo doesn’t require overhauling your infrastructure. It’s compatible with leading inference engines:
- vLLM: Officially supported with Multi-Token Prediction enabled via
num_speculative_tokens=1. This unlocks faster inference without code changes. - SGLang: Full support for MiMo with EAGLE-based speculative decoding for additional speedups.
- Hugging Face Transformers: Plug-and-play via
AutoModelForCausalLMwithtrust_remote_code=True.
The recommended prompt format uses an empty system prompt, simplifying integration. For optimal performance—especially inference speed—using the vLLM or SGLang backends is advised to leverage MTP.
When (and When Not) to Choose MiMo
MiMo is ideal for:
- Applications requiring strong mathematical or programming reasoning under latency or cost constraints.
- Research projects exploring efficient reasoning architectures or RL for code/math.
- Deployments where 7B-scale models are preferred for on-premise or edge inference.
However, MiMo is not designed as a general-purpose chatbot. Its strengths lie in structured, logic-driven tasks—not open-ended conversation or creative writing. Additionally, to replicate benchmark results, use temperature=0.6 and the recommended inference stack.
Summary
MiMo redefines what’s possible in a 7B language model. By co-designing pretraining and post-training around reasoning from the ground up, it achieves performance that rivals or exceeds models many times its size—without sacrificing deployability. Whether you’re building a coding tutor, a math solver, or a STEM reasoning agent, MiMo offers a compelling blend of efficiency, accuracy, and ease of use. With open weights and robust community support via Hugging Face and ModelScope, it’s ready for real-world adoption today.