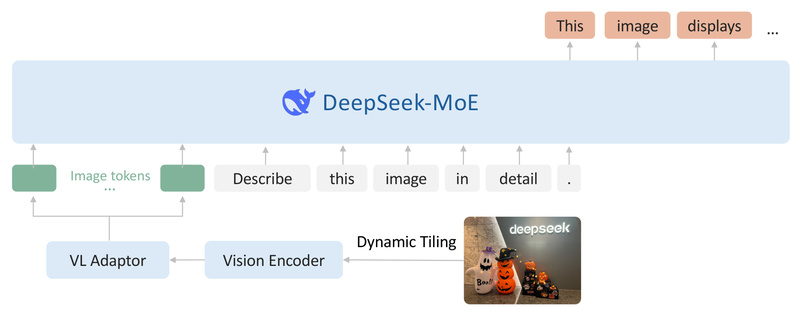
DeepSeek-VL2 is an open-source, advanced vision-language model (VLM) built on a Mixture-of-Experts (MoE) architecture, engineered for robust multimodal understanding across a wide range of real-world tasks. Released by DeepSeek AI, it significantly enhances its predecessor, DeepSeek-VL, through two key innovations: a dynamic tiling strategy for processing high-resolution images of varying aspect ratios, and a language backbone powered by the DeepSeekMoE architecture featuring Multi-head Latent Attention. This attention mechanism compresses Key-Value (KV) caches into compact latent vectors, enabling faster inference and higher throughput without sacrificing accuracy.
The DeepSeek-VL2 family includes three model variants—DeepSeek-VL2-Tiny, DeepSeek-VL2-Small, and DeepSeek-VL2—with 1.0B, 2.8B, and 4.5B activated parameters, respectively. Despite their relatively modest activated parameter counts, these models consistently achieve competitive or state-of-the-art performance on benchmarks involving visual question answering (VQA), optical character recognition (OCR), document/table/chart comprehension, and visual grounding. Crucially, DeepSeek-VL2 delivers this performance using fewer activated parameters than many existing dense and MoE-based open-source VLMs, making it a compelling choice for developers and researchers seeking efficiency without compromise.
Key Innovations That Drive Performance
Dynamic Tiling for High-Resolution Visual Input
Traditional vision encoders often struggle with high-resolution images or those with non-standard aspect ratios, either downscaling them (losing critical detail) or applying fixed cropping strategies (introducing bias). DeepSeek-VL2 addresses this with a dynamic tiling vision encoding strategy that intelligently partitions images based on resolution and aspect ratio, preserving fine-grained visual information while maintaining computational feasibility. This is particularly valuable for OCR and document understanding tasks where small text or dense layout elements must be accurately interpreted.
Efficient Inference via Multi-head Latent Attention
The language component of DeepSeek-VL2 leverages the DeepSeekMoE architecture, enhanced with Multi-head Latent Attention. This novel mechanism compresses the KV cache—typically the main memory bottleneck during autoregressive generation—into a smaller set of latent vectors. As a result, the model supports longer context processing, reduces memory footprint during inference, and increases generation speed, all while retaining high-quality multimodal reasoning.
This efficiency gain is not just theoretical: DeepSeek-VL2 enables inference on hardware with tighter memory constraints. For example, DeepSeek-VL2-Small can run on a 40GB GPU using incremental prefilling, a technique that processes long inputs (including image embeddings) in chunks to avoid memory overflow.
Practical Applications and Use Cases
DeepSeek-VL2 excels in scenarios requiring deep integration of visual and textual understanding:
- Visual Question Answering (VQA): Answer complex questions about image content, including reasoning over scenes, objects, and relationships.
- Document & Chart Understanding: Parse structured content such as invoices, spreadsheets, bar charts, and scientific figures—extracting both semantic meaning and spatial layout.
- Optical Character Recognition (OCR): Accurately read text in natural scenes or scanned documents, even under challenging conditions like low resolution or irregular fonts.
- Visual Grounding: Localize specific objects mentioned in a prompt using special tokens like
<|ref|>,<|/ref|>, and<|det|>. For example, given the prompt “<|ref|>The giraffe at the back.<|/ref|>,” the model can return bounding box coordinates wrapped in<|det|>[[x1, y1, x2, y2]]<|/det|>.
These capabilities make DeepSeek-VL2 well-suited for applications in enterprise automation (e.g., intelligent document processing), assistive technologies, robotics, and educational tools.
Getting Started: Simple and Flexible Inference
Using DeepSeek-VL2 is straightforward thanks to its integration with the Hugging Face transformers ecosystem. After installing the package (pip install -e .), users can load any model variant and run inference with just a few lines of code.
For single-image tasks, the model accepts a conversation-style input with embedded image placeholders (<image>) and optional grounding tokens. For multi-image or interleaved image-text inputs, users can reference multiple images in sequence—ideal for comparative analysis or multi-step visual reasoning.
The library also supports incremental prefilling, which is essential for running larger variants like DeepSeek-VL2-Small on 40GB GPUs. By setting a chunk_size (e.g., 512 tokens), the model processes long multimodal sequences in manageable segments, preserving memory while maintaining output quality.
A lightweight Gradio demo is provided for quick experimentation, though users are advised to deploy with optimized backends like vLLM or SGLang for production use due to the demo’s lack of performance tuning.
Practical Considerations and Licensing
While DeepSeek-VL2 is highly capable, it does come with hardware considerations. Running DeepSeek-VL2-Small without optimization typically requires around 80GB of GPU memory; the Tiny variant (1.0B activated parameters) is more accessible on consumer-grade hardware.
From a licensing perspective, the codebase is MIT-licensed, while the models are released under the DeepSeek Model License, which explicitly permits commercial use—a significant advantage for industry adoption.
Why Choose DeepSeek-VL2 Over Alternatives?
In a landscape crowded with increasingly large and resource-intensive vision-language models, DeepSeek-VL2 stands out by delivering state-of-the-art or competitive performance with fewer activated parameters. Its MoE design ensures that only a subset of experts is activated per token, leading to better compute efficiency during both training and inference.
Combined with its support for high-resolution inputs, strong grounding capabilities, and open availability—including weights, code, and evaluation support via VLMEvalKit—DeepSeek-VL2 offers a rare balance of accuracy, efficiency, and accessibility. For teams evaluating VLMs for real-world deployment, it represents a cost-effective, future-ready solution that doesn’t require massive infrastructure to get started.
Summary
DeepSeek-VL2 redefines what’s possible in open-source vision-language modeling by merging architectural innovation with practical usability. Through dynamic tiling, latent attention, and a carefully scaled MoE design, it enables advanced multimodal understanding across diverse tasks—while remaining efficient enough for real-world deployment. Whether you’re building a document intelligence system, an assistive visual assistant, or a research prototype, DeepSeek-VL2 provides a powerful, flexible, and commercially viable foundation.