Building intelligent voice interfaces used to mean stitching together separate speech recognition (ASR), text generation, and text-to-speech (TTS) systems—each with its own quirks, data requirements, and alignment challenges. Step-Audio changes that. It’s the first production-ready, open-source framework that unifies speech understanding and generation in a single architecture, enabling developers and researchers to build truly interactive, expressive, and multilingual voice agents without the prohibitive costs or brittle pipelines of legacy approaches.
Launched by StepFun AI, Step-Audio isn’t just another research prototype. It’s designed from the ground up for real-world deployment, offering fine-grained control over voice attributes, built-in voice cloning, and agent-like reasoning—all while delivering state-of-the-art performance across ASR, TTS, and conversational tasks. If you’re building voice-enabled products—whether customer service bots, educational tutors, or creative audio tools—Step-Audio offers a rare combination of capability, openness, and practicality.
A Single Model That Does It All
At the heart of Step-Audio lies a 130-billion-parameter multimodal language model called Step-Audio-Chat. Unlike conventional systems that treat speech input and output as separate stages, this model processes and generates both text and audio within a unified framework.
How? Step-Audio tokenizes audio using a dual-codebook system: one codebook (1024 entries) captures semantic meaning at 16.7 Hz, while another (4096 entries) encodes fine-grained acoustic details at 25 Hz. These are interleaved in a 2:3 temporal ratio, allowing the model to jointly reason about what is being said and how it sounds.
This unified design eliminates the need for hand-engineered pipelines. The same model can:
- Transcribe speech to text (ASR)
- Understand spoken queries and generate intelligent responses
- Synthesize natural-sounding speech from text (TTS)
- Clone a speaker’s voice from a short audio sample
All of this runs through one coherent neural architecture, dramatically simplifying deployment and ensuring consistent alignment between understanding and generation.
Instruction-Driven Voice Control: Emotion, Dialect, Speed, and Style
One of Step-Audio’s most compelling features is its instruction-based voice control system. Instead of hardcoding voice parameters, you simply describe what you want in natural language:
“Speak in a joyful tone, but slow down for emphasis.”
“Answer in Sichuanese dialect with a calm, reassuring voice.”
“Rap the response in English with high energy.”
Thanks to extensive supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF), Step-Audio reliably follows these instructions. It supports:
- Emotions: joy, sadness, anger, calm, excitement
- Dialects: Cantonese, Sichuanese, and more (within Chinese)
- Prosodic styles: rap, a cappella humming, singing
- Speech rate: from ultra-slow enunciation to rapid-fire delivery
This level of expressiveness was previously only available in proprietary, cloud-based APIs. Step-Audio brings it into the open-source ecosystem—free to use, modify, and deploy.
Affordable Voice Cloning Without Massive Datasets
Traditional TTS systems require hours of clean, studio-recorded speech per speaker—a major barrier for personalized voice applications. Step-Audio solves this with a generative speech data engine.
Using the 130B model, the team synthetically generates high-quality, diverse speech data, which is then used to distill a lightweight Step-Audio-TTS-3B model. This 3B-parameter model retains strong instruction-following and voice cloning capabilities but runs on far more accessible hardware (just 8GB GPU memory).
To clone a voice, you only need:
- A short audio clip (~5–10 seconds)
- The corresponding transcript
The system then replicates the speaker’s timbre, pitch, and rhythm—enabling personalized assistants, audiobook narrators, or character voices in games without costly data collection.
Enhanced Intelligence for Complex Interactions
Step-Audio isn’t just a voice synthesizer—it’s an intelligent agent. Its architecture integrates tool calling and role-playing capabilities, allowing it to:
- Fetch real-time information via API calls
- Maintain consistent character traits during multi-turn dialogues
- Handle complex, multi-step voice tasks (e.g., “Book a flight, then summarize the itinerary in a cheerful voice”)
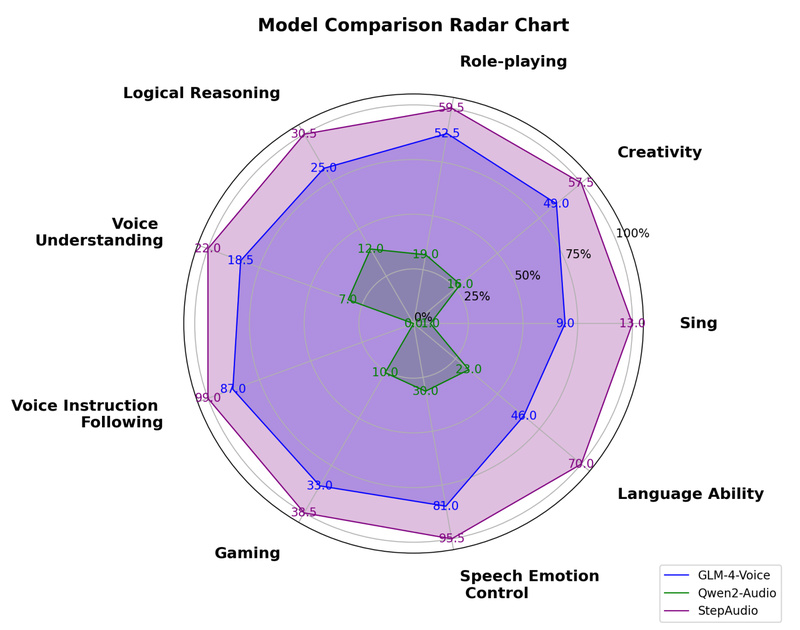
This is validated on StepEval-Audio-360, a new benchmark with 137 real-user, multi-turn Chinese prompts testing dimensions like logical reasoning, creativity, gaming interaction, and emotional control. Step-Audio-Chat outperforms competitors like GLM-4-Voice and Qwen2-Audio across nearly all categories.
Getting Started: Flexible Deployment Options
Step-Audio provides multiple entry points depending on your needs:
- Step-Audio-Chat (130B): Full unified model for end-to-end speech understanding and generation. Requires ~265GB GPU memory—best suited for server deployment with 4×A800/H800 GPUs.
- Step-Audio-TTS-3B: Lightweight TTS and voice cloning model. Runs on a single 8GB GPU, ideal for resource-constrained environments.
- Step-Audio-Tokenizer: Standalone audio tokenizer for preprocessing.
You can run inference via:
- Command-line scripts (
offline_inference.py,tts_inference.py) - Local web demos (
app.py,tts_app.py) - Docker containers for reproducible environments
- vLLM integration (recommended for Step-Audio-Chat) for high-throughput, tensor-parallel text generation (note: audio input isn’t supported in vLLM mode)
All models are available on Hugging Face and ModelScope, with installation instructions and dependency management via Conda.
Performance You Can Trust
Benchmarks confirm Step-Audio’s real-world advantage:
- ASR: Achieves 0.87% CER on Aishell-1—best among open models, outperforming Whisper Large-v3 (5.14%) and Qwen2-Audio (1.53%).
- TTS: Delivers the lowest content error rates (CER/WER) on Chinese and English test sets, with 1.17% CER for the full TTS model—surpassing CosyVoice and FireRedTTS.
- Voice Instruction Following: Scores 4.4/5 on voice control and 4.0/5 on singing/RAP—nearly double GLM-4-Voice’s scores.
- General Knowledge: On the LLaMA Question benchmark, Step-Audio-Chat scores 81.0%, a 9.3% average improvement over prior models.
These results aren’t just academic—they reflect consistent, human-preferred performance in dynamic, real-time interactions.
Practical Limitations to Consider
Step-Audio is powerful, but not without constraints:
- The full Step-Audio-Chat model requires 265GB GPU memory, making it impractical for edge or consumer devices.
- Audio input is not supported in vLLM mode, limiting real-time speech interaction in that high-throughput setup.
- Optimal performance assumes Linux + CUDA and high-end NVIDIA GPUs (A800/H800 recommended).
- Model weights are open but governed by specific license terms (separate from the Apache 2.0-licensed code).
For many applications, the Step-Audio-TTS-3B model offers a compelling balance of quality and accessibility.
Summary
Step-Audio redefines what’s possible with open-source voice AI. By unifying understanding and generation in a single, instruction-aware model, it eliminates traditional bottlenecks in data, pipeline complexity, and expressive control. Whether you’re building a multilingual customer service agent, an emotionally intelligent companion, or a creative audio tool that raps in Cantonese, Step-Audio provides the foundation to do it—openly, affordably, and at production quality. With strong benchmarks, flexible deployment options, and real-world readiness, it’s a compelling choice for anyone serious about advancing speech interaction beyond today’s limitations.